COMP 3511: Lecture 11
Date: 2024-10-10 14:55:18
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
CPU Scheduling Algorithms
- 👨🏫 assume: all under single processor system
-
First-Come First-Served: FCFS
- if arrives in respective order
- waiting time: each process in "ready stage"
- time joining CPU burst - arrival time
- ⭐⭐ = turn-around time - CPU burst time
- turn-around time: total time to execute a particular process
- ⭐⭐ = completion time - arrival time
- (for single process system)
- 👨🏫 waiting & turn around time: must be computed manually
- earlier system: FCFS = one program is scheduled to run until completion
- in multiprogramming systems: process finishes its current CPU time
- example

- waiting time:
- avg.waiting time:
- avg. turn-around time:
- or:
- example 2

- waiting time:
- avg.waiting time:
- avg. turn-around time:
- Convoy effect: short process: stuck behind a long process
- bad for short jobs, depending purely on arrival order
- e.g. one CPU -bund & many IO-bound processes
- FCFS: result in low IO device utilization
- problem: you can't know execution time of the program beforehand!
-
Round Robin (RR)
- straightforward solution
- if process takes longer than expectation (e.g. found from the curve)
- FCFS: non-preemptive
- once CPU core allocated process, process keeps it until release
- RR: preemptive
- each process w/ small unit of CPU time (time quantum )
- 10-100 ms
- after time elapse: process is preempted and added to the end of ready queue
- each process w/ small unit of CPU time (time quantum )
- given long process, each process: gets portion of CPU time
- per each round
- (ignoring context switching)
- waiting time: always less than time units
- timer: interrupt every quantum to schedule next process / process blocks
- upon completing current CPU burst time
- when its CPU burst time / remaining CPU time
- i.e. quicker than expectation?
- example: w/

- waiting time:
- avg. waiting time:
- avg. turn-around time:
- response time:
- average: 7
- i.e. first response time - request time
- 👨🏫 same as turn-around for FCFS/FIFO
- remaining CPU burst time
- average waiting time: can be long
- but inherently "fairer" than FCFS
- offers better average response time: important for interactive jobs
- straightforward solution
-
Time quantum and context switch time
- performance of RR: depends heavily on choice
- large : FCFS
- small : interleaved, but high overhead from context switch time
- context switch time: micro sec
- performance of RR: depends heavily on choice
-
FCFS - RR comparison
-
is RR: always better than FCFS?
-
extreme example: quantum = 1
- and 10 jobs starting same time, with 100 CPU burst time
Job # FIFO RR 1 100 991 2 200 992 9 900 999 10 1000 1000 -
average job turn-around time: much worse
- albeit with two extreme conditions
- very small quantum size
- all jobs with same length
- yet: average response time: much better
- albeit with two extreme conditions
-
example
process time 6 3 1 6 -
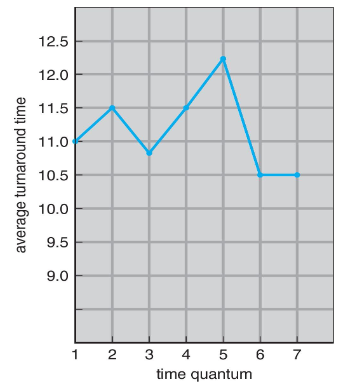
turnaround time: varies with time quantum
- average turnaround time: not necessarily improve when quantum increases
- it can be, generally, when most processes finish current CPU bursts within a single quantum
- yet: large quantum leads to FCFS
-
⭐ rule of thumb: 80% of CPU bursts: should be shorter than the time quantum
- quantum: should be enough to produce meaningful result for most cases
-
👨🏫 can be adjusted on the way
- actually... we have better algorithms than pure RR
-
-
Short-Job-First (SJF)
- what if: we know next CPU burst time of each process?
- then, we can process the shorted job first
- for given set of processes, this is optimal (i.e. min avg. waiting time)
- difficulty: knowing length of next CPU request
- big effect on short jobs, rather than long ones
- more precise name: shortest-next-CPU-burst
- can be applied to entire program / current CPU burst only
- response time: not concerned now
- 👨🏫 as this is introduction of concepts
- example
process time 6 8 7 3 
- average waiting time:
- best FCFS = case of SJF
- actually,
-
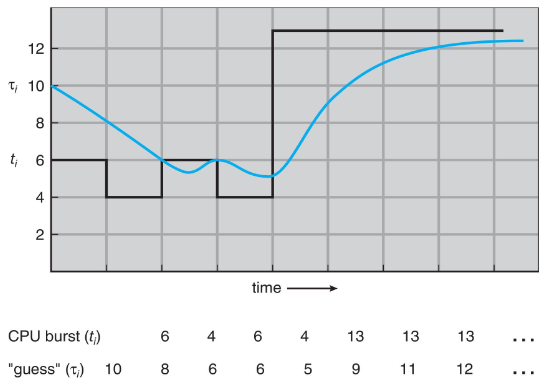
Determining length of next CPU burst
-
estimation: done by exponential average (again :p)
- : average length of -th burst
- : predicted value for next CPU burst
-
- larger : weight / portion of the most recent data
- define:
-
commonly:
-
preemptive version: called shorted-remaining-time-first (SRTF)
diagram
-
examples of EMA
- :
- first estimation lasts forever
- :
- only last CPU burst counts
- current prediction: dependent on all of past data
- yet, the effect of past exponentially reduces
- :
-