COMP 3511: Lecture 21
Date: 2024-11-14 15:02:44
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Page Replacement
-
Least recently used (LRU) algorithm
- 👨🏫 approximates optimal
- use the past knowledge for approximation for OPT
- 👨🏫 based on locality!
- replace: page that has not been used for the most amount of time
- associate: time of last use w/ each page
- 👨🏫 complex as table: must be updated w/ each memory reference
- associate: time of last use w/ each page
- generally good & frequently used algorithm
- implementation: may require hardware assistance
- determine an order for frames defined by time of last use
-
LRU implementation
- counters implementation
- every page entry: adds time-to-use field recording logical clock / counter
- clock: incremented for every memory reference
- whenever reference to page made: clock registers are copied to time-of-use field
- to choose victim: look for counters w/ smallest value
- every page entry: adds time-to-use field recording logical clock / counter
- stack implementation
- keep: stack of a page number
- whenever a page is referenced: remove from stack
- and put on the top
- most recently used: always at top
- bottom: always at the bottom
- requires: multiple pointers to be changed upon each reference
- each update: more expensive
- yet, no need to search for replacement
- 👨🏫 performance wise, either implementation is "not very good"
- although frequency used
- counters implementation
-
LRU discussions
- LRU / OPT: case of stack algorithms not suffering from Belady's Anomaly
- shows that: set of pages in memory for frame: ALWAYS subset of pages it would have with frames
- for LRU: most recently referenced most recently referenced
- both implementation: requires extra hardware replacement
- updating clock fields / stack: must be done for every memory reference!
- LRU / OPT: case of stack algorithms not suffering from Belady's Anomaly
-
LRU approximation algorithms
- reference bit
- each page: associate a bit (initially 0)
- associated w/ each PTE
- when referenced: set it to 1
- replace any w/ reference bit (if any)
- course-grained approximation:
- order of use: not known
- 👨🏫 what is the least recently used? can't answer always
- course-grained approximation:
- each page: associate a bit (initially 0)
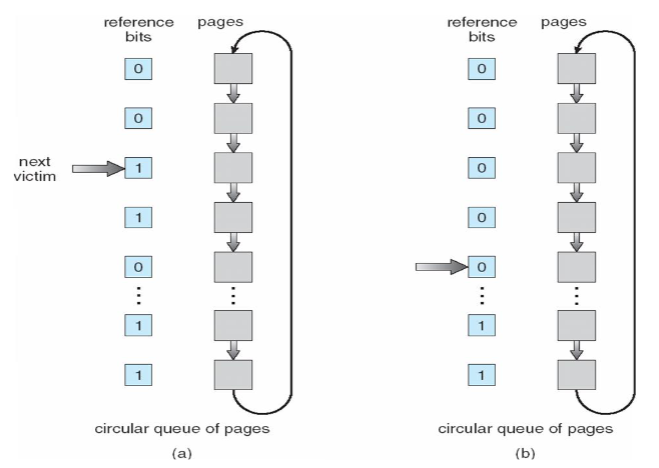
- second-chance algorithm
- FIFO order + hardware-provided reference bit w/ clock replacement
- if page to be replaced has:
ref. bit = 0: replace (as victim)ref. bit = 1: set ref. bit0, leave page in memory- i.e. second chance
- replace next page, w/ the same rule (FIFO + clock)
- 👨🏫 complexity: can be avoided as you can move pointer somewhat - without random accessing
- FIFO itself: not very good, as it doesn't approximate optimal
- advantage: simple implementation
- reference bit
-
Counting algorithms
- keep counter on: no. of references that have been made
- 👨🏫 2 different rationals!
- least frequently used (LFU) algorithm: replaces the page w/ smallest count
- most frequently used (MFU) algorithm: replaces the page w/ most count
- 👨🏫 maybe: it has been already used all!
- neither replacement: commonly used
- expensive implementation & no approximation
- for special systems
-
Allocation of frames
- how to: allocate memory among different processes?
- same freaction, forfifferent?
- should we completely swap some process out of memory?
- each process: needs some minimum no. of frams in order to execute the program
- IBM example
- maximum: total frames required for a process
- two major allocation schemes
- fixed allocation
- priority allocation
- many variations
- how to: allocate memory among different processes?
-
Fixed allocation
- equal allocation
- proportional allocation
- 👨🏫 useless in modern OS!
-
Global vs. local allocation
- global replacement
- process: selects a replacement frame from the set of all frames
- even if the frame: allocated to some other process
- one can take a frame from another process
- e.g. based on priority (priority allocation w/ preemption, basically)
- might result in better system throughput
- yet, execution time many very greatly
- page-fault rate: cannot be self-controlled
- not very consistent!
- process: selects
- process: selects a replacement frame from the set of all frames
- local replacement
- 👨🏫 most common!
- might result in: underutilized memory
- as pages: cannot be utilized to another
- yet: more consistent per-process performance
- global replacement
-
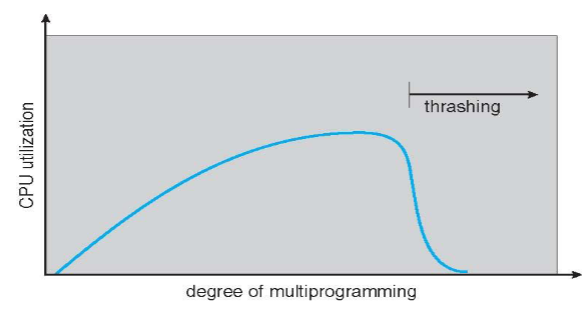
Threshing
- when a process: w/o enough pages
- page-fault rate: will be very high
- leads to low CPU utilization
- OS: "thinks" that degree of multiprogramming must be increased to improve utilization
- 👨🏫 aggravate the problem!
- OS: "thinks" that degree of multiprogramming must be increased to improve utilization
- thrashing: process / set of processes busy swapping pages in & out
- aka high paging activity
- process: thrashing if more time is spent paging than executing
- when a process: w/o enough pages
-
Demand paging & thrashing
- demand paging: warks w/ locality model
- locality model: set of pages that are actively used together
- running program: usually composed of multiple localities over time
- memory access / subsequent memory access: tent to stay ni the same set of pages
- process: migrates from one locality to another
- e.g. operating on different set of data / function call
- locality: might overlap
- locality model: set of pages that are actively used together
- thrashing occurs when:
- size of locality (of all process) total memory size
- allocating not enough frames to accommodate the size of current locality
- effect: can be limited using local replacement
- one: cannot cause other process to thrash!
- locality in memory-reference pattern
- demand paging: warks w/ locality model
-
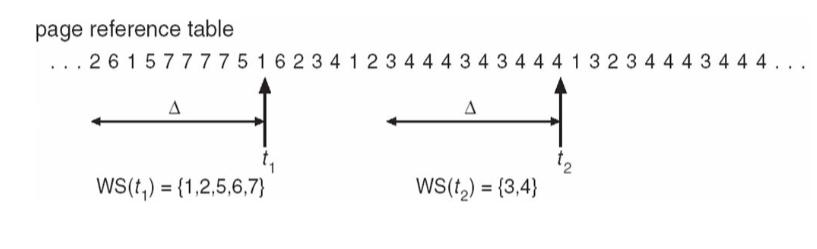
Working-set model
- working-set window a fixed no. of page references
- e.g. 10,000 instructions
- : working set of process :
- total no. of distinctive pages referenced in most recent
- varies in time
- too small : cannot encompass entire locality
- too large : encompass several localities
- too : encompass entire program
- total no. of distinctive pages referenced in most recent
- total demand frames
- approximation of current locality in the system (of all process)
- if : thrashing (at least one process: short of memory)
- policy: if , then suspend / swap out one of the processes
- working-set strategy: prevents thrashing
- while: keeping the degree of multiprogramming as high as possible
- 👨🏫 CPU utilization: optimized!
- difficulty: keeping track of the working set
- while: keeping the degree of multiprogramming as high as possible
- working-set window a fixed no. of page references
-
Keeping track of the working set
- keeping track of working set: difficult
- as the window: is a sliding window updated w/ each memory reference
- approximate w/ interval timer + reference bit
- e.g.
- timer: interrupts after every time units
- keep in memory: 2 bits for each page
- whenever a timer interrupts: copy & set the values of all ref. bits to 0
- if 1ne of the bits in memory = 1: page in working set
- not accurate, as we can't tell where in interval the reference occurred
- improvement: use 10 bits w/ interrupt every time units
- more accurate, yet more expensive
- accuracy vs. complexity
- keeping track of working set: difficult
-
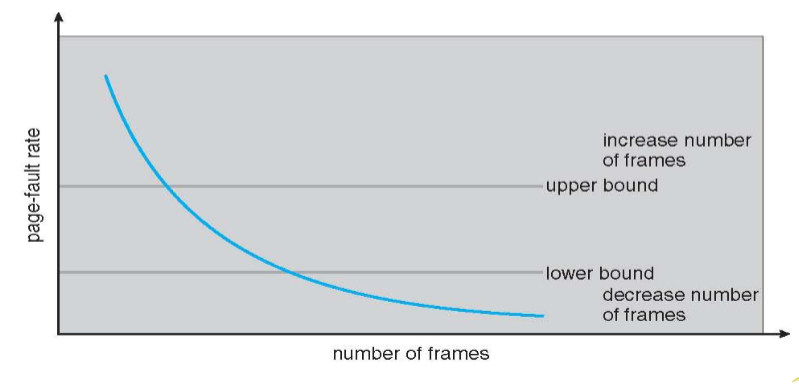
Page-fault frequency
- more direct approach than WSS
- establish "acceptable" page-fault frequency (PFF) rate & use local replacement policy
- if: actual rate too low -> process loses frame
- if: actual rate too high -> process gains frame
- upon migration to different locality: may be temporary high PFF
-
Working sets and page-fault frequency
- relationship between working set of a process & page-fault rate
- working set: changes over time
- PFF of process: transitions between peaks & valleys over time
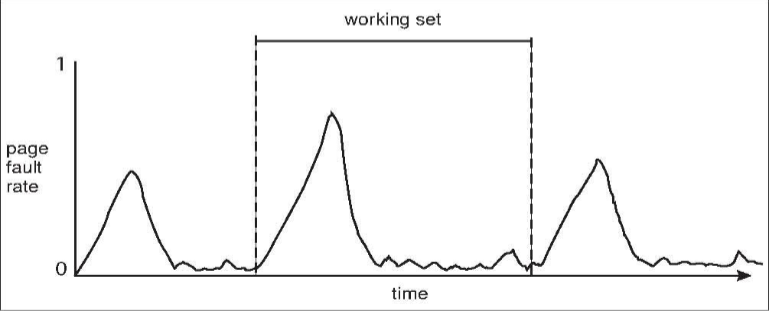
- 👨🏫 only general diagram!
Other considerations
-
Prepaging
- reduce: large no. of page faults occurring at process startup
- prepage some pages the process will need
- before they are referenced
- if: prepaged pages unused => IO & memory wasted
- assume: pages are prepaged, of pages are used
- is cost of save pages faults more than the cost of preparing unnecessary pages
- near 0: prepaging loses
-
Page size
- sometimes, OS designers have a choice
- esp. on custom-built CPU
- page size selection: must consider conflicting set of criteria
fragmentation: calls for smaller page sizepage table size: calls for larger page sizeresolution: isolate the memory actually be used
- always power of 2, usually in range of
- on average: growing over time
- sometimes, OS designers have a choice
-
TLB reach
- TLB reach: amount of memory accessible from the TLB
- TLB reach:
- 👨🏫 ideally!
- ideally: working set working set of each process: stored in the TLB
- otherwise: potentially high degree of page faults / slow access
- increase the page size
- leads to: increase in fragmentation, as not all applications: requires a large page size
- provide multiple page sizes
- allows applications require larger page sizes
- to use larger pages w/o increase in fragmentation
- allows applications require larger page sizes