COMP 3511: Lecture 13
Date: 2024-10-17 15:00:44
Reviewed:
Topic / Chapter:
summary
❓Questions
- ❓ if one process happens to miss deadline once in a cycle, will it miss deadline again in the next cycle?
- 👨🏫 maybe, maybe not! depends on arrival, deadline, etc.
- ❓ what if: we know in prior that a process will miss deadline?
- depends on whether the deadline is soft or hard
- also, different mechanism handles it differently
- for hard deadline, you may ignore the step in some cases
- if the workload is >100% (impossible), it's not scheduler's problem!
Notes
Other Scheduling (cont.)
-
Multicore processor
- recent trend: multiple processor cores on same physical chip
- faster & consumes less power
- but: complicate scheduling design
- memory stall: waits long time waiting for memory / cache to respond
- as processors are much faster than memory
- 👨🏫 inherent problem of Von-Neumann architecture
- solution: having multiple hardware threads per core
- each hardware thread: w/ own state, PC, register set
- appearing as a logical CPU: running a software thread
- chip multithreading (CMT)
- 👨🏫 dealing with two program, without idle state!
- ideal case
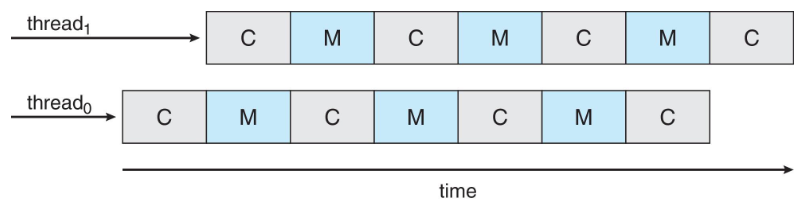
- 👨🏫 in reality: memory operation might be much longer than CPU operation
- then, we can have more hardware threads than just 2
- each hardware thread: w/ own state, PC, register set
- scheduling: can take advantage of memory stall
- to make progress on another hardware thread, while another doing memory task
- core: switching to another thread - dual-thread processor core
- 👨🏫 there is no software overhead, as it's hardware
- thus, it's very fast
- dual-threaded, dual-core system: presents 4 logical processors to OS!
- e.g. UltraSPARC T3 CPU: w/ 16 cores / chip and 8 hardware threads per core
- appearing to be 128 logical processors
- e.g. UltraSPARC T3 CPU: w/ 16 cores / chip and 8 hardware threads per core
- recent trend: multiple processor cores on same physical chip
-
Multithreaded multicore system
- from OS view: each hardware thread maintains its architecture state
- thus: appears as a logical CPU
- CMT: assigns each core multiple hardware threads
- Intel term: hyperthreading
- 👨🏫 logical != physical
- you can't simultaneously run all those jobs
- two levels of scheduling exist
- OS: decide which SW thread to run on a logical CPU (in CPU scheduling)
- each core: decide which hardware to run on physical core
- possible: RR scheduling
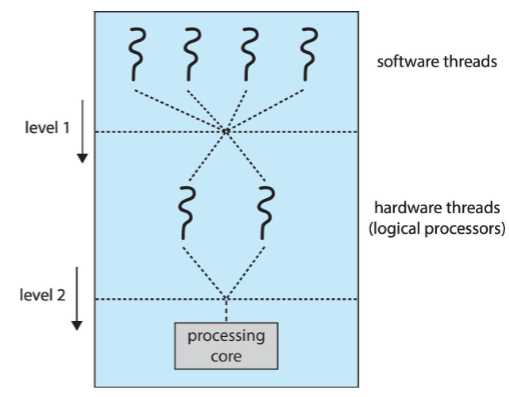
- from OS view: each hardware thread maintains its architecture state
-
Multithreaded multicore scheduling
- user-level thread: schedule to LWP / kernel-level thread
- for many-to-one or many-to-many: thread library schedules user-level threads
- such threads: process contention scope (PCS)
- typically: based on priority (set by programmers)
- for many-to-one or many-to-many: thread library schedules user-level threads
- software thread (=kernel thread): scheduled on logical CPU = hardware thread
- 👨🏫 OS is responsible for this only
- hardware thread: scheduled to run on a CPU core
- each CPU core: decides scheduling, often using RR
- user-level thread: schedule to LWP / kernel-level thread
Processor Allocation
-
Processor affinity
- process: has affinity for a processor on which it runs
- cache contents of processor: stores on memory accesses by that thread
- called as processor affinity
- cache contents of processor: stores on memory accesses by that thread
- high cost of invalidating in repopulating caches
- most SMP: try to avoid migration!
- essentially: per-processor ready queues: provide processor affinity for free
- soft affinity: OS: attempts to keep process running on same processor (no guarantee)
- possible for process to migrate: during load balancing
- hard affinity: allow a process to specify: subset of processors it may run
- 👨🎓 I want this, that, and this only!
- many systems: provide both soft & hard affinity
- e.g. Linux implements soft affinity, yet also provides syscall
sched_setaffinity()for hard affinity
- e.g. Linux implements soft affinity, yet also provides syscall
- process: has affinity for a processor on which it runs
-
Load balancing
- 👨🏫 only focusing on load balancing: common queue for all cores are good
- same for separate queue and affinity
- everything comes at a cost!
- load balancing: attempts to keep workload evenly distributed
- two general approaches to load balancing
- push migration: specific task: periodically check load on each processor
- if imbalance found: pushes overloaded CPU's task to less-busy CPUs
- pull migration: idle processors: pull waiting tasks from a busy processor
- not mutually exclusive: can be both implemented in parallel on load-balancers
- e.g. Linux CFS implements both
- push migration: specific task: periodically check load on each processor
- load balancing: often counteracts benefits of processor affinity
- natural tension between load balancing & minimizing memory access times
- scheduling algorithms for modern multicore NUMA systems: quite complex
- 👨🏫 only focusing on load balancing: common queue for all cores are good
-
Real-time CPU scheduling
- demands: performance guarantee - predictability
- especially in embedded control, etc.
- e.g. spaceship must respond within certain time
- hard real-time systems: with stricter requirements
- task: must be serviced by deadline
- service after deadline: expired, and meaningless
- soft real-time systems
- provides: no guarantee to when critical real-time process will be scheduled
- guarantee tha real-time process: given preference over noncritical process
- 👨🏫 we will be discussing this now!
- must support: priority-based algorithm w/ preemption
-
Priority-based scheduling
- processes: w/ periodic characteristic: requires CPU at constant intervals (periods)
- has: processing time , deadline , period :
- 👨🏫 if : CPU must always be working on this
- rate of periodic task:
- has: processing time , deadline , period :
- process: must announce its deadline requirements
- scheduler: decides whether to admit process or not
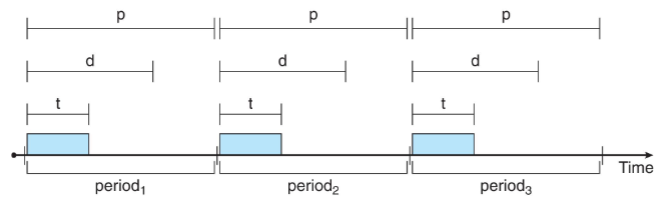
- processes: w/ periodic characteristic: requires CPU at constant intervals (periods)
-
Rate monotonic scheduling
- static priority: assigned based on inverse of period
- shorter period: higher priority
- rationale: assign priority to frequent (CPU) visitor
- suppose:
- w/ period=deadline 50, processing time 20
- w/ period=deadline 100, processing time 35
- as : w/ higher priority than
- : occupied time
- : occupied time
- 👨🏫 75% utility if both can be scheduled!
- if the sum is more than 100%: can't be scheduled at all
- schedule example
- 👨🏫 is tricky - it's preemptive!
- missing deadline
- w/ period=deadline 50, processing time 25
- w/ period=deadline 70, processing time 35
- as : w/ higher priority than
- : occupied time
- : occupied time
- 👨🏫 94% utility if both can be scheduled!
- P2: missing deadline by finishing at time 85

- static priority: assigned based on inverse of period
-
Earliest deadline first scheduling (EDF)
- Earliest deadline first: assigns priorities dynamically according to deadline
- earlier the deadline: higher the priority
- e.g. w/ same case as above:

- 👨🏫 "first" has higher priority than "first"
- but second has lower priority than first
- no preemption of first by second !
- notably: first () preempts second ()
- 👨🏫 logically equivalent to SRTF
- Earliest deadline first: assigns priorities dynamically according to deadline
-
Rate-monotonic vs. EDF scheduling
- rate-monotonic: schedules periodic tasks w/ static priority w/ preemption
- considered optimal among static priority-based algorithm
- EDF: does not require process to be periodic, nor constant CPU burst time
- only requirement: process announce deadline when it becomes runnable
- EDF: theoretically optimal
- schedule processes s.t. each process: meet deadline requirements
- and CPU utilization will be 100 percent
- in practice: impossible to achieve such level
- as: cost of context switching & interrupt handling, etc.
- optimal: cannot find a better scheduler w/ smaller number of deadline misses
- rate-monotonic: schedules periodic tasks w/ static priority w/ preemption

Algorithm Evaluation
-
Algorithm evaluation
- selecting CPU scheduling algorithm: might be difficult
- different algorithms: w/ own set of parameters
- selecting CPU scheduling algorithm: might be difficult
-
Deterministic modeling
- takes: particular predetermined workload
- and define: performance of each algorithm for that workload
-
Queueing analysis
- through actual numbers (arrival time, CPU bursts, etc.)
- 👨🏫 there can be 2 PG courses on this!
- Queueing models
- mathematical approach for stochastic workload handling
- : average queue length
- : average queue length
- : average arrival rate into queue
- usually given
- Little's formula:
- 👨🏫 my PhD thesis owa on this :p
- more details: Poisson and Markov chain...
- 👨🏫
- : CPU burst time
- unless: overload :p
-
Simulations
- queueing models: not "very" practical, but interesting mathematical models
- restricted to few known distributions
- more accurate: simulations involving program of a computer system model:
- queueing models: not "very" practical, but interesting mathematical models
-
Simulation implementation
- even simulations: w/ limited accuracy
- build a system: allowing actual algorithms to run w/ real data set
- more flexible & general
- 👨🏫: no true optimal solution exists