Introduction
information
These are my notes on COMP 3511: Operating Systems As I was enrolled to the course only after the add-drop, some of my early notes (lecture 1-4; lab 1) might be less organized.
Course information
- Course code: COMP 3511
- Course title: Operating Systems
- Semester: 24/25 Fallcon
- Credit: 3
- Grade: A-F
- TMI
- Prerequisites: COMP 2611 OR [(ELEC 2300 OR ELEC 2350) AND (COMP 2011 OR COMP 2012H)]
- Exclusion: N/A
Description
This is an introductory course on operating systems. The topics will include the basic concepts of operating systems, process and threads, inter-process communications, process synchronization, scheduling, memory allocation, page and segmentation, secondary storage, I/O systems, file systems, and protection. It contains the key concepts as well as examples drawn from a variety of real systems such as Microsoft Windows and Linux.
My section
- Section: L2 / LA2
- Time:
- Lecture: TuTh 03:00PM - 04:20PM
- Lab: Mo 03:00PM - 04:50PM
- MT: October 25, 06:30PM - 09:30PM
- Venue:
- Lecture: LT-G
- Lab: G010, CYT Bldg
- Instructor: Li, Bo
- email: [email protected]
- Teaching Assistants:
- Project
- Peter CHUNG ([email protected])
- PA 1-3 related questions
- Tao FAN ([email protected])
- PA 1 grading & appealing
- Tianyi BAI ([email protected])
- PA 2,3 grading & appealing
- Peter CHUNG ([email protected])
- Homework
- Jingcan CHEN ([email protected])
- HW 1 grading & appealing
- Feiyuan ZHANG ([email protected])
- HW 2 grading & appealing
- Xingxing TANG ([email protected])
- HW 3 grading & appealing
- Peng YE ([email protected])
- HW 4 grading & appealing
- Jingcan CHEN ([email protected])
- Lab
- Peter CHUNG ([email protected])
- Teaching PA-related labs (Lab 3,5,8)
- Zhonghan CHEN ([email protected])
- Teaching Lab 1,2
- Yijun SUN ([email protected])
- Teaching Lab 4,6
- Junze LI ([email protected])
- Teaching Lab 7,9
- Peter CHUNG ([email protected])
- Project
Grading scheme
| Assessment Task | Percentage |
|---|---|
| Mid-Term | 20% |
| HW | 20% |
| Projects | 30% |
| Final Exam | 30% |
Required texts
- Abraham Silberschatz, Peter B. Galvin, Greg Gagne John Wiley & Sons Ltd, April 2018. Operating System Concepts, 10th Edition, MIT Press.
Optional resources
- Remzi Arpaci-Dusseau & Andrea Arpaci-Dusseau. Operating Systems: Three Easy Pieces
COMP 3511: Lecture 1
Date: 2024-09-26 13:41:44
Reviewed:
Topic / Chapter: Basic OS
summary
❓Questions
Notes
Introduction to the Course
-
Introduction
- learning goals
- fundamental principles, strategies, and algorithms
- for design & implementation of operating systems
- analyze & evaluate OS functions
- understand basic structure of OS kernel
- and identify relationship between various subsystems
- identify typical events / alerts / symptoms
- indicating potential OS problems
- design & implement programs for basic OS functions and algorithms
- fundamental principles, strategies, and algorithms
- course overview
- overview (4)
- basic OS concept (2)
- system architecture (2)
- process and thread (12)
- process and thread (4)
- CPU scheduling (4)
- synchronization and synchronization example (2)
- deadlock (2)
- memory and storage (8)
- memory management (2)
- virtual memory (3)
- secondary storage (1)
- file systems and implementation (2)
- protection (1)
- protection (1)
- security - optional
- overview (4)
- learning goals
Operating System
-
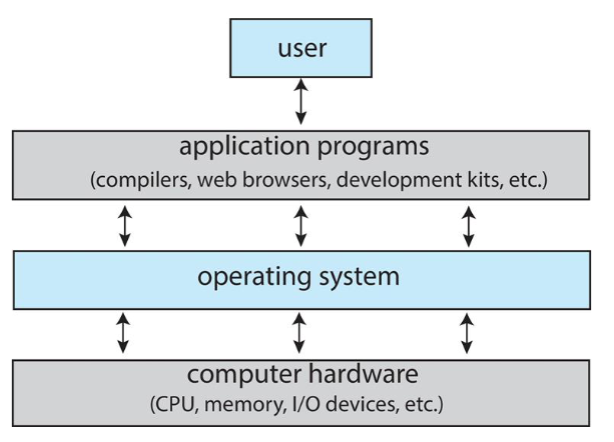
Operating system components
- users: people, machine, other computers / devices
- application programs: defining ways how system resources are used
- to solve user problems
- e.g. editors, compilers, web browsers, video games, etc.
- operating system: controls & coordinates use of computing resources
- among various application & different users
- hardware: basic computing resources: CPU, memory, IO devices
-
Operating system introduction
- OS: a (complex) program working as intermediary between: user-applications and hardware
- iOS, MS Window, Android, Linux, etc.
- OS goals:
- execute user programs & solve user problems easier
- make computer system: convenient to use
- manage & use computer hardware efficiently
- user view:
- convenience, easy of use, good performance & utility
- user: doesn't care about resource utilization & efficiency
- system view:
- OS: resource allocator & control program
- no universally accepted definition, but:
- "everything vendors ships when you order an OS"
- OS as a resource allocator
- managing both SW & HW resources
- decides among conflicting requests: for efficient & fair resource use
- OS as a control program
- controls: execution of programs, prevent errors & improper use of computer
- OS: manages & controls hardware
- helps to facilitate (user) programs to run
- OS: a (complex) program working as intermediary between: user-applications and hardware
-
OS breakdown
- kernel: one program always running on computer
- provides essential functionalities
- middleware: set of SW frameworks: provide additional services to app dev
- e.g. DB, multimedia, graphics
- popular in mobile OS
- all else:
- system programs
- application programs
- OS includes:
- always running kernel
- middleware frameworks: for easy app development & additional feature
- system programs: aid in managing system while running
- kernel: one program always running on computer
-
Operating system tasks
- depends on: PoV (user vs. system) and target devices
- shared computers (mainframe, minicomputer)
- OS: need to keep all users satisfied
- performance vs. fairness
- individual systems (e.g. workstations) with dedicate resources
- performance > fairness; may use shared resource from servers
- mobile devices: resource constrained
- target specific user interfaces (touch screen, voice detection)
- optimized for usability & battery life
- computers / computing devices w/ little-no UI
- embedded systems: present within home devices, automobiles, etc.
- run real-time OS
- design: run primarily without user intervention
- embedded systems: present within home devices, automobiles, etc.
Computer System Organization
-
Computer system organization
- one or more CPU cores & device controllers: connected through common bus
- providing access to shared memory
- goal: concurrent execution of CPUs and devices
- compete for memory cycles w/ shared bus
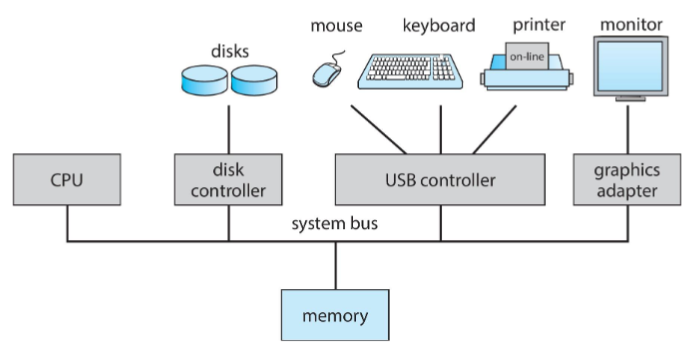
- compete for memory cycles w/ shared bus
- one or more CPU cores & device controllers: connected through common bus
-
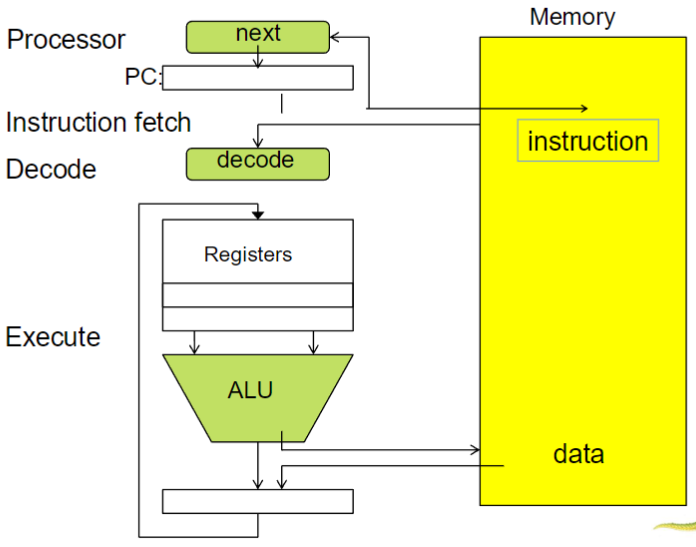
Von Neumann architecture: composition
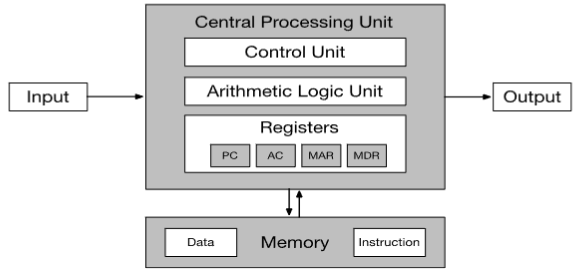
- CPU: contains ALU & processor registers
- programmer counter (PC)
- accumulator (AC)
- memory address register (MAR)
- memory data register (MDR)
- control unit: contains
- instruction register (IR)
- program counter (PC)
- memory: w/ data and instructions
- as well as caches
- external mass storage / secondary storage for more space
- input-output mechanism
- CPU: contains ALU & processor registers
-
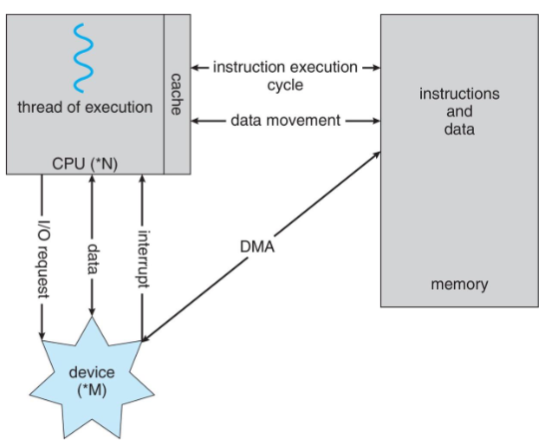
Von Neumann architecture
- steps
- fetch instruction
- decode instruction
- fetch data
- execute instruction
- write back (if any)
diagrams
- steps
COMP 3511: Lecture 2
Date: 2024-09-29 21:40:37
Reviewed:
Topic / Chapter: Interrupts & Storage
summary
❓Questions
Notes
Interrupts
-
IO
- IO device & CPU: execute concurrently & asynchronously
- ~= event driven?
- each device controller: in charge of a particular device
- w/ local buffer
- responsible for moving data between:
- peripheral devices it control
- & local buffer storage
- IO operation: from device -> local buffer of controller
- CPU: moves data from/to main memory local buffers
- typically: for slow devices (keyboard, mouse)
- DMA controller: to move data for fast devices (e.g. disks)
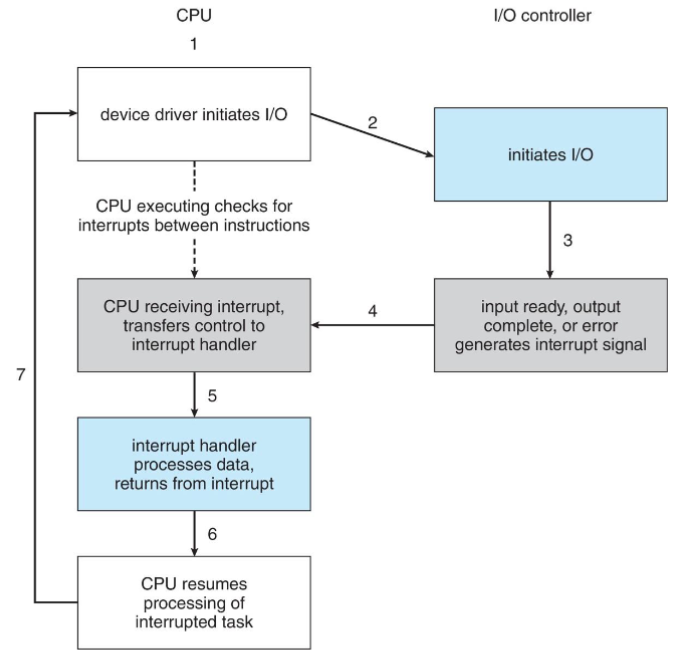
- device controller: informs CPU operation termination (completion / fail) by: interrupt
- i.e. requires CPU attention
- for input: i.e. data is available in local buffer
- for output: i.e. IO operation has been completed
- IO device & CPU: execute concurrently & asynchronously
-
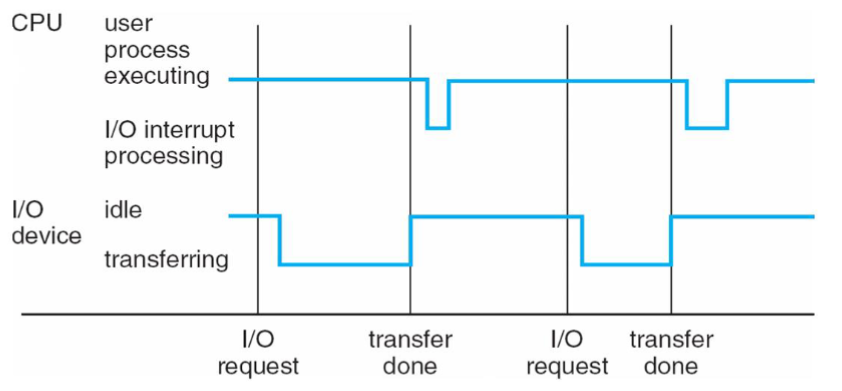
Interrupt cycle
-
Interrupt timeline
- CPU & device: execute concurrently
- IO device: may trigger interrupt by sending CPU a signal
- CPU handles interrupt (i.e. transfer control to interrupt handler)
- then returns to interrupted instruction
-
Interrupt functions
- interrupts: widely used in modern OS systems
- for asynchronous event handling
- e.g. device controllers hardware faults
- all modern OS: interrupt-driven
- hundreds of interrupts occur per sec
- CPU: extremely fast ()
- hundreds of interrupts occur per sec
- interrupt: transfers control to:
- interrupt service routine / interrupt handler
- part of kernel code; OS runs to handle a specific interrupt
- also: implements a interrupt priority levels
- high-priority interrupt: can preempt execution of low-priority
- trap / exception: SW-generated interrupt caused either by:
- error (e.g. div by 0) / user request (e.g. some syscall)
- interrupts: widely used in modern OS systems
Storage
-
Bits & Units
- bit: basic unit of computer storage (0/1)
- byte: 8 bits
- smallest chunk of storage from most computers
- word: computer architecture's native unit of data
- nowadays: mostly
1 word = 8 byte = 64 bits
- nowadays: mostly
- larger units
- kilobyte bytes
- megabyte bytes
- gigabyte bytes
- terabyte bytes
- petabyte bytes
- often rounded up in for computer manufacturers
- however, network measurements: given in bits, not bytes
-
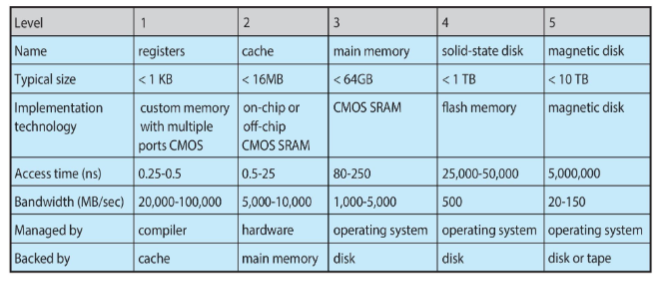
Storage hierarchy
- storage systems: organized in hierarchy
- w/ speed, cost / unit, capacity, and volatility (non-volatile vs. volatile)
- usually, higher: faster & more expensive, but smaller & more volatile
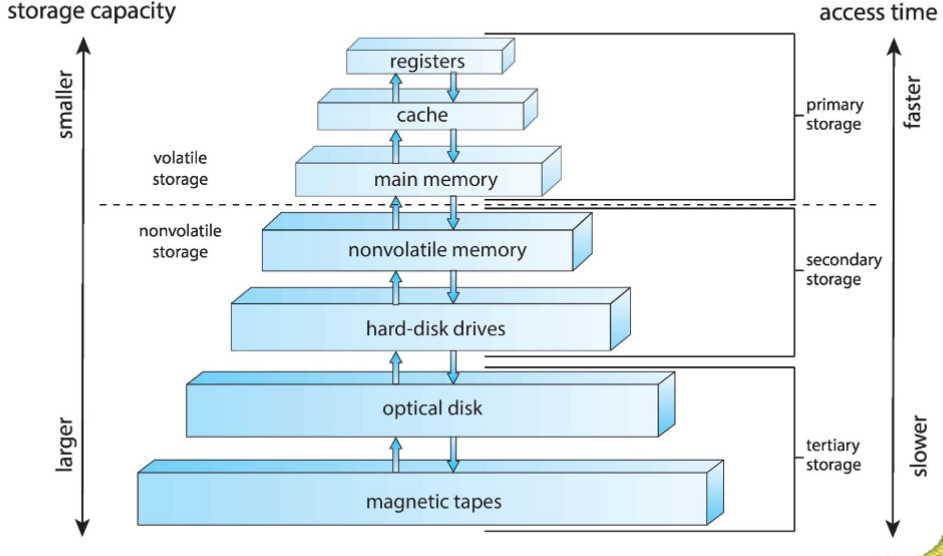
- storage systems: organized in hierarchy
-
Memory
- main memory: directly accessible by CPU
- only large storage media to be so
- volatile, often random-access memory
- in the form of: dynamic ram (DRAM)
- basic operations:
load&storeto specific memory address- that is: byte addressable
- each addr: refers to 1 byte in memory
- computers: also use other forms of memory
- main memory: directly accessible by CPU
-
Second storage
- i.e. extension of main memory
- w/ non-volatile storage capacity
- data: stored permanently
- most common such storage:
- hard disk drives (HDD)
- nonvolatile memory (NVM) devices
- provides storage for both programs & data
- generally: two types
- mechanical
- HDDs, optical disks, holographic storage, magnetic tape
- generally larger & less expensive
- electrical
- flash memory, SDD, FRAM, NRAM
- electrical: often referred as NVM
- typically costly, smaller, more reliable & faster
- mechanical
-
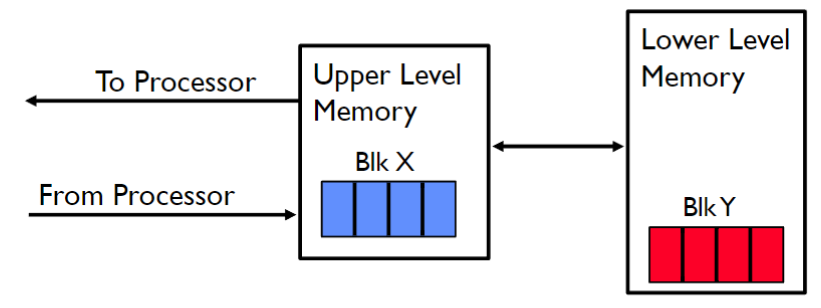
Caching
- important: performed at many levels in computers
- for memory, address translation, file blocks, file names (freq. used), file dir, network routes, etc.
- ⭐ fundamental idea: a subset of information: copied from slower to a faster storage temporarily
- i.e. make freq. used case: faster
- access: first check whether information is inside cache
hit: inside cache; information can be directly retrieved (fast)miss: not inside cache; data copied from slower storage to cache, then used (slow)
- cache: usually much smaller than storage (memory) being cached
- cache management: cache size & replacement policy
- major criteria: cache hit ratio; percentage of hit per access
- important measurement
- important: performed at many levels in computers
-
Locality: principle below caching
- temporal locality (in time)
- recently accessed items: likely to be accessed again
- spatial locality (in space)
- contiguous blocks (i.e. neighbor of recently accessed): likely to be accessed shortly
- without locality pattern (i.e. all item: accessed w/ equal prob): cache can't work
- temporal locality (in time)
COMP 3511: Lecture 3
Date: 2024-10-02 02:10:47
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Storage / IO
-
Cache levels
-
range of timescales
name time (ns) L1 cache reference 0.5 branch mispredict 5 L2 cache reference 7 mutex lock/unlock 25 main memory reference 100 compress 1K bytes w/ Zippy 3,000 send 2K bytes w/ 1 Gbps net 20,000 read 1 MB sequentially from memory 250,000 round trip within same data center 500,000 disk seek 10,000,000 read 1 MB sequentially from disk 20,000,000 send packet CA->Netherlands->CA 150,000,000
-
-
IO subsystem
- OS: accommodate wide variety of devices
- w/ different capabilities, control-bit def., protocol to interact
- OS: enables standard, uniform way of interaction w/ IO
- involving abstraction, encapsulation, and software layering
- encapsulate device behavior in generic classes
- each: accessed through interface: standardized set of functions
- one purpose of OS: hide gap between hardware devices from users
- abstraction & encapsulation!
- IO subsystem: responsible for
- memory management of IO
- buffering: storing data temporarily while being transferred
- caching: storing parts of data in faster storage for performance
- spooling: overlapping / queuing of one job's output as input of other jobs
- typically: printers
- general device-driver interface
- driver for specific hardware devices
- memory management of IO
- OS: accommodate wide variety of devices
-
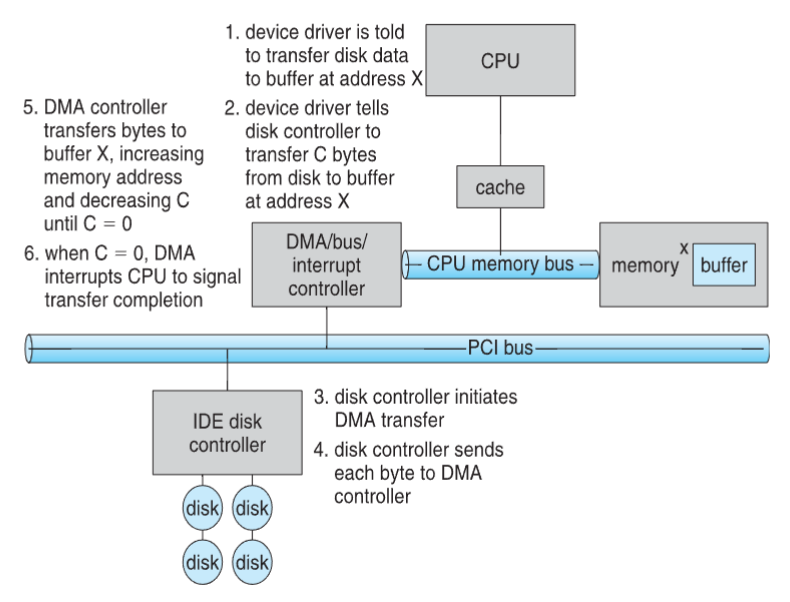
Direct memory access
- programmed IO: CPU running special IO instructions
- moving byte one-by-one
- between memory & slow devices (keyboard & mouse)
- for fast devices: programmed IO must be avoided
- instead, use direct memory access (DMA) controller
- idea: let IO device and memory transfer data directly
- bypass CPU!
- CPU / OS initialize DMA controller, and it's now responsible for moving data
- benefit: CPU freed from slow IO operations
- OS writes DMA command block into memory
- preparation
- source & destination addresses
- read || write mode
- no. of bytes to be transferred
- execution
- write location of command block to DMA controller
- bus mastering of DMA controller
- i.e. grab bus from CPA
- send interrupt to CPU for signaling completion
- preparation
DMA transfer diagram
- programmed IO: CPU running special IO instructions
Processors
-
Single processor system
- traditionally: most system w/ single processor, single CPU, single processing core
- core: executes instructions & registers for storing data locally
- processing core / CPU: capable of executing a general-purpose instruction set
- such systems: w/ other special-purpose processors
- e.g. device-specific processors (for disk) and graphic controllers (GPU)
- those: w/ limited instruction set
- not executing instructions from user processes
- traditionally: most system w/ single processor, single CPU, single processing core
-
Multiprocessor system
- modern computer (mobile to servers): dominated by multiprocessors system
- traditionally: 2+ processors and each w/ single-core CPU
- speedup ratio: less than no. of processors
- due to overhead - contention for shared resources
- e.g. bus / memory
- multiprocessor advantage
- increased throughput: more computing capability
- economy of scale: share other devices (e.g. IO devices)
- increased reliability: graceful degradation / fault tolerance
- two types of multiprocessor systems
- asymmetric multiprocessing
- master-slave manner
- master processor: assign specific tasks to slaves
- master: handles IO
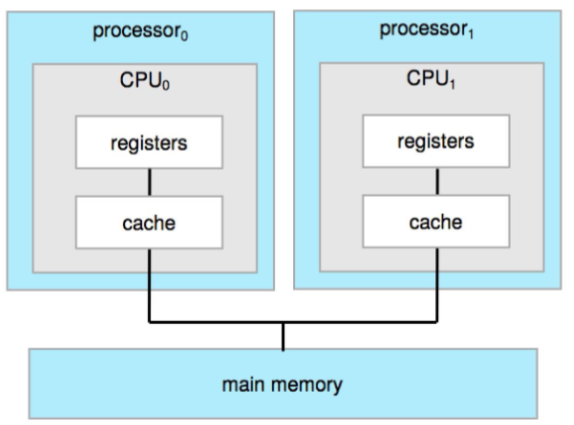
- symmetric multiprocessing
- each processor: performs all tasks
- including OS functions & user processes
- aka SMP
- each processor: w/ own set of registers and private || local cache
- but all processors: share physical memory via system bus
- each processor: performs all tasks
- asymmetric multiprocessing
- multicore: multiple computing cores inside a single physical chip
- faster intra-chip communication than inter-chip
- using significantly less power: important for mobile / laptops
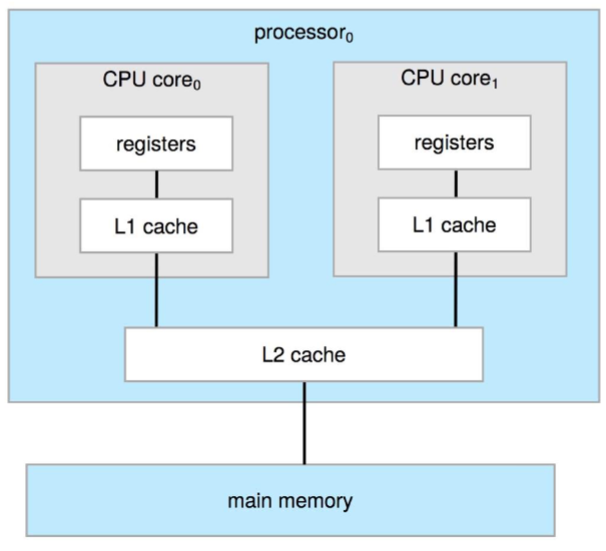
- modern computer (mobile to servers): dominated by multiprocessors system
-
Non-Uniform Memory Access (NUMA)
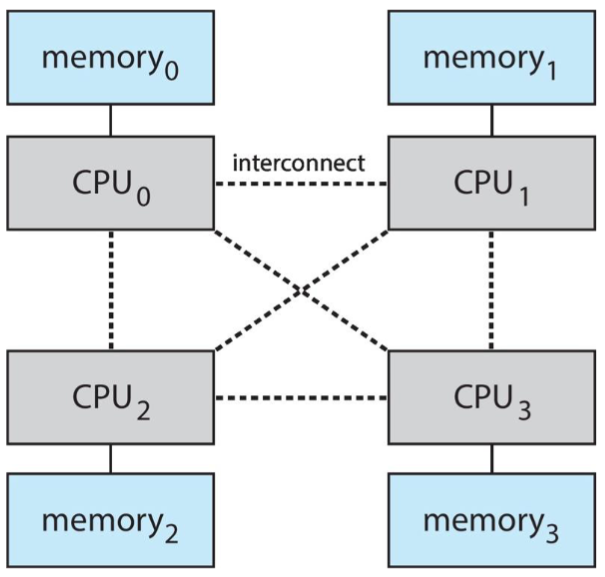
- adding more CPU to multiprocessor: may not scale / help
- as system bus can be a bottleneck
- alternative: provide each CPU local memory
- accessed via small & fast local bus
- CPUs: connected by shared system interconnect
- all CPU: share one physical memory address space
- such approach: non-uniform memory access (NUMA)
- potential drawback
- increased latency when CPU must access remote memory across system interconnect
- e.g. memory of another CPU?
- scheduling & memory management implication
- increased latency when CPU must access remote memory across system interconnect
-
Computer system component
- CPU: hardware executing instructions
- processor: physical chip containing one or more CPUs
- core: basic computation unit of CPU
- or: component executing instructions / registers for storing data locally
- multicore: including multiple computing cores on a single physical processor chip
- multiprocessor system: including multiple processors
OS Structure
-
OS structure
- 2 common characteristics exist in all modern OS
- multiprogramming: for efficiency
- aka batch system
- single program: can't keep CPU & I/O busy
- thus multi-program: organize multiple jobs
- s.t. CPU will not stay idle
- in mainframe PC: jobs being submitted remotely & queued
- selected & ran via jab scheduling: load into the memory
- timesharing: logical extension of multiprogramming
- aka multitasking
- CPU: switches frequently between jobs
- s.t. users: can interact w/ each job while running
- enables: interactive computing
- characteristics
- response time:
- each user: w/ at least one program executing in memory (= process)
- if several jobs ready to run: CPU scheduling needed
- if: processes don't fit in memory
- swapping technique required
- moving some program in and out of memory during execution
- virtual memory: allows execution of processes that are not completely in memory
Virtualization
-
Virtualization
- virtualization: abstracts hardware of a single computer
- into multiple different execution environments
- creating illusion: each user / program is running on their "private computer"
- creates: virtual system = virtual machine (VM) to run OS / applications over
- allows: an OS to run as an app within another OS
- 👨🏫 growing industry!
- allows: an OS to run as an app within another OS
- into multiple different execution environments
- components
- host: underlying hardware system
- virtual machine manager (VMM): creates & runs VM by providing interface
- s.t. it's identical to the host
- aka hypervisor
- guest: process provided w/ virtual copy of host
- i.e. program. often: an OS (guest OS)
- allows: a single physical machine to run multiple OS concurrently
- each on their own VM
system models
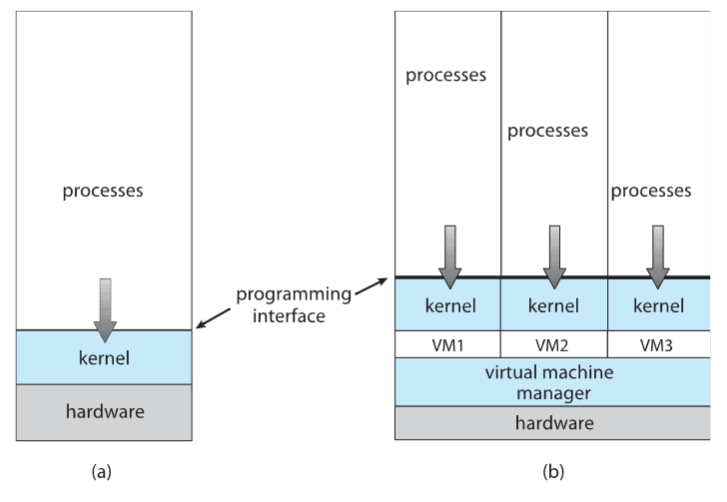
- virtualization: abstracts hardware of a single computer
-
Virtualization history
- virtualization: OS natively compiled for CPU, running guest OSes
- originally: designed in IBM mainframes (1972)
- for: allowing multiple users to run tasks concurrently
- under: system designed for a single use
- or: sharing batch-oriented system
- for: allowing multiple users to run tasks concurrently
- VMware: runs one or more guest copies of Windows on Intel x86 CPU
- virtual machine manager (VMM): provides environment for programs
- that is: essentially identical to original machine (interface)
- programs on such environment: only experience minor performance decrease (due to extra layers)
- VMM: in complete control of system resources
- originally: designed in IBM mainframes (1972)
- by late 1990s: Intel CPUs on general purpose PCs: fast enough for virtualization
- technology: treated by , which are still relevant today
- virtualization: expended to many OSes, CPUs, VMMs
- virtualization: OS natively compiled for CPU, running guest OSes
COMP 3511: Lecture 4
Date:
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Cloud Computing
-
Cloud computing & virtualization
- delivers: computing, storage, or apps as a service over a network
- logical extension of virtualization: combination of virtualization & communication
- Amazon EC2: w/ millions of servers, and tens of millions of VMs
- petabytes of storage available across the Internet
- payment: based on usage
- Amazon EC2: w/ millions of servers, and tens of millions of VMs
-
Cloud types
- public cloud: available vis Internet to anyone willing to pay
- private: run by company for internal use
- hybrid cloud: includes both public & private components
- software as a service (SaaS): provides one / more apps via Internet (web based application)
- no installation required
- platform as a service (PaaS): provides SW stack ready for application via Internet
- e.g. database server, Google Apps Engine, Heroku
- infrastructure as a service (IaaS): provides servers / storage over Internet
- e.g. VM instances, cloud bucket
- other services: also appearing
- e.g. machine learning as a service (MaaS)
Free & Open Source
-
Free and open source OS
- OS: often made available in source code, rather than just binary
- yet: MS Windows: closed source
- idea: started by Free Software Foundation (FSF) w/ "copyleft" GNU Public License (GPL)
- free software != open-source software
- free software: licensed to allow no-cost use, redistribution, modification
- in addition to public source
- open source: not necessarily w/ such license
- popular examples:
- GNU / Linux
- FreeBSD UNIX (and core of MAx OS X - Darwin)
- Solaris
- open source code: arguable more secure
- more programmers to contribute & check
- a better learning tool for us
- OS: often made available in source code, rather than just binary
OS Services
-
OS services
- OS: provides environment for execution of programs
- and other services to programs & users
- set of OS services (OS functions) helpful to user
- user interface: almost all OS has a user interface (UI)
- command line (CLU), graphics (GUI), touch-screen
- program execution: system: must be able to load program into memory
- and run the program & end execution
- either normally or abnormally (= error)
- and run the program & end execution
- IO operations: running program: may require IO
- might involve: files / IO device
- ⭐ file-system manipulation: programs: need to read & write files and directories
- in additions to: search, create, and delete
- and further: listing file information / permission management
- communications: processes: may exchange information (on same computer, or over a network)
- via: shared memory or through message passing (packets: moved by the OS)
- error detections: OS needs to be constantly aware of possible errors
- may occur in CPU, memory, IO devices, user programs
- for each error type: OS must take appropriate actions
- to ensure: correct & consistent computing
- debugging facilities: can greatly enhance the user's and programmer's abilities
- to efficiently use the system
- user interface: almost all OS has a user interface (UI)
- other set of OS services: ensures efficient operation of system (via resource sharing)
- resource allocation: within multiple concurrent users & jobs
- resources: must be allocate to each of them
- e.g. CPU cycles, memory, file storage, IO devices
- resources: must be allocate to each of them
- logging: keep track of: which users use how much
- and what kinds of computer resources
- protection, security: owners of information stored in multi-user / networked system: might want control on information use
- e.g. permission control
- concurrent processes: should not interfere with each other
- protection: involving ensuring that all accesses to system resources: controlled
- security of the system from outsiders: requires user authentication
- extends to: defending external IO devices from invalid access attempts
- resource allocation: within multiple concurrent users & jobs
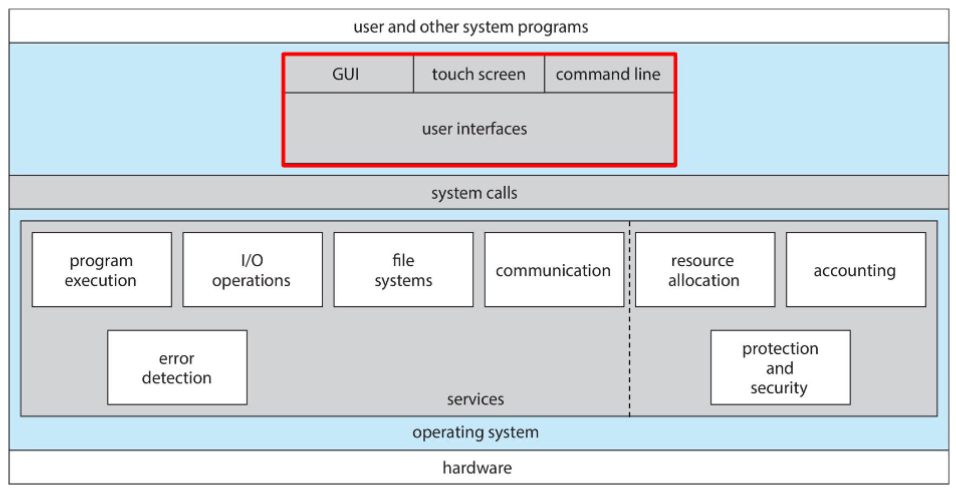
- OS: provides environment for execution of programs
-
User OS interface: CLI
- generally: three approaches for UI exists
- CLI / command interpreter - directly enters commands to OS
- GUI / touch screen: allows user to interface w/ the OS
- CLI: allows direct command entry
- sometimes: implemented in kernel
- sometimes by system programs
- sometimes: multiple flavors implemented: shells in Unix / Linux
- primary functionality of shell:
- fetching command from user
- interpreting it
- executing it
- UNIX and Linux systems: provide different version of shells
- e.g. C shell, Bourne-Again, Korn, et.
- sometimes: implemented in kernel
- generally: three approaches for UI exists
-
User OS interface: GUI
- user-friendly desktop metaphor interface
- usually: mouse, keyboard, and monitor
- icons representing files, programs, directories, system functions, etc.
- various mouse buttons over objects: cause various actions
- e.g. provide information, execute function, open directory, etc.
- invented at: Xerox PARC earlier 1970s (near Stanford)
- first wide use: in Apple Macintosh (1984)
- many systems now: provide both CLI and GUI interfaces
- MS Windows: using GUI w/ CLI command shell
- Apple Max OS X: Aqua GUI interface
- w/ UNIX kernel underneath, as well as shells
- Unix and Linux: w/ CLI and optional GUI interfaces (KDE, GNOME)
- user-friendly desktop metaphor interface
-
User OS interface: touchscreen
- touch screen requires: new interfaces
- mouse: not feasible / desired
- actions & selection: based on gestures (no mouse move)
- virtual (on-screen) keyboard for text
- voice command: iPhone's Siri, etc.
- touch screen requires: new interfaces
Syscall
-
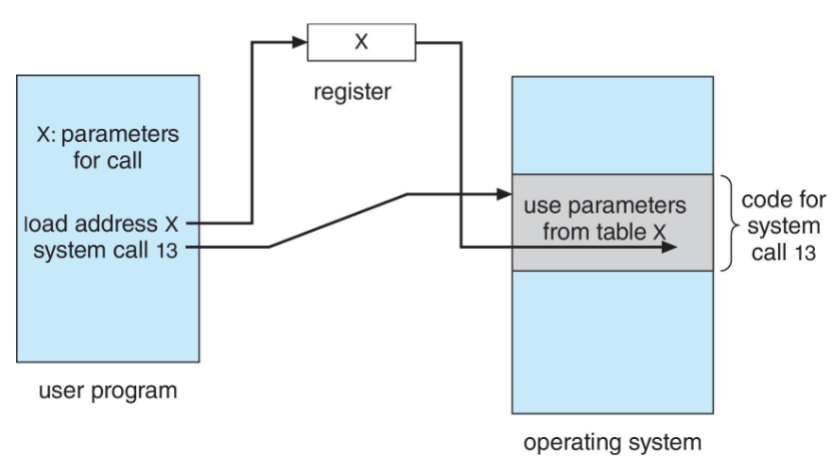
Syscall
- system call: programming interface to the services provided by the OS
- syscall: generally available as functions, written in a high-level language (C/C++)
- certain low-level tasks: written in assembly languages (accessing hardware)
- e.g.:
cp in.txt out.txtinvolves multiple syscall- input file name, accept input, open input file, create out file, etc.
-
API
- application program interface (API): specifying a set of functions, available for app programmers to use
- including: parameters passed to functions
- and expected return values
- including: parameters passed to functions
- function making up API: typically invoke actual syscalls, on behalf of programmer
- programmer: access APIs via library provided by the OS
- in UNIX / Linux:
libcfor C programs
- in UNIX / Linux:
- three most common APIs:
- Win32 API for Windows systems
- POSIX API for POSIX-based systems (UNIX, Linux, and Mac OS X)
- Java API for JVM
- standard API example
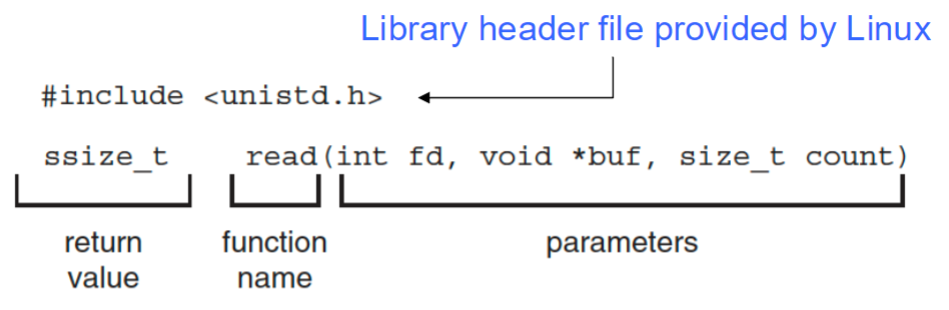
- parameters
int fd: file descriptor to be readvoid *buf: buffer the data will be read intosize_t count: maximum number of bytes to be read: into the buffer
- return value
0: indicating end of file-1: indicating error
- advantages: why use API over syscall?
- program portability: programmer w/ API: expect program to run on any system supporting same API
- syscall implementation: might vary from machine to machine
- abstraction: hiding complex details of the syscall from users
- actual syscall: often more details / difficult to work with
- caller of API: doesn't need to know implementation of syscall
- caller: simply obey API format / understand what does API do
- program portability: programmer w/ API: expect program to run on any system supporting same API
- application program interface (API): specifying a set of functions, available for app programmers to use
-
Syscall implementation
- for most programming languages: run-time environment (RTE) provides syscall interface
- serving as link to syscalls, made available by OS
- RTE: set of functions built into libraries
- each syscall: associated w/ identity number
- syscall interface: maintains a table indexed according to these numbers
- syscall interface: functions
- intercept: function calls in API
- invoke: necessary syscall within OS
- return: status of syscall / return values if any
- API-syscall-OS relationship
- for most programming languages: run-time environment (RTE) provides syscall interface
-
Syscall parameter passing
- often: more info than just syscall identity is needed
- exact type / amount of information: vary for OS / call
- 👨🏫 although we will spend some time on a syscall without parameter (
fork())
- three general methods used to pass parameters from user programs to OS
- simplest: pass parameters in registers
- block method: parameters stored in block / table / memory
- and address of block: passed as a parameter in a register
- stack method: parameters placed / pushed onto stack by the program
- popped off the stack by the OS
- block & stack: no limitation on number / length of parameters!
- parameter passing: via table
- often: more info than just syscall identity is needed
-
Types of syscalls
- process control
- create / terminate process
- end, abort
- load, execute
- get / set process attributes
- wait for time
- wait even, signal event
- allocate / free memory
- dump memory if error
- debugger for determining bugs, single step execution
- locks for managing access to shared data between processes
- file management
- create / delete file
- open / close file
- read, write, reposition
- get & set file attributes
- device management
- request / release device
- read, write, reposition
- get / set device attributes
- logically attach / detach devices
- information maintenance
- get & set time / data
- get & set system data
- get & set process, file, device attributes
- communications
- create, delete communication connection
- send, receive messages: to host name / process name
- if message parsing model
- shared memory model: create & gain access to memory regions
- transfer status information
- attach & detach remote devices
- protection
- control access to resources / get and set permissions
- allow / deny user access
- process control
-
Examples
task Windows Unix process control CreateProcess()fork()ExitProcess()exit()WaitForSingleObject()wait()file management CreateFile()open()ReadFile()read()WriteFile()write()CloseHandle()close()device management SetConsoleMode()ioctl()ReadConsole()read()WriteConsole()write()information maintenance GetCurrentProcessID()getpid()SetTimer()alarm()Sleep()sleep()communications CreatePipe()pipe()CreateFileMapping()shm_open()MapViewOfFile()mmap()protection SetFileSecurity()chmod()InitializeSecurityDescriptor()umask()SetSecurityDescriptorGroup()chown()- standard C library example
- program invoking
printf()library call- leads to
write()syscall, etc. 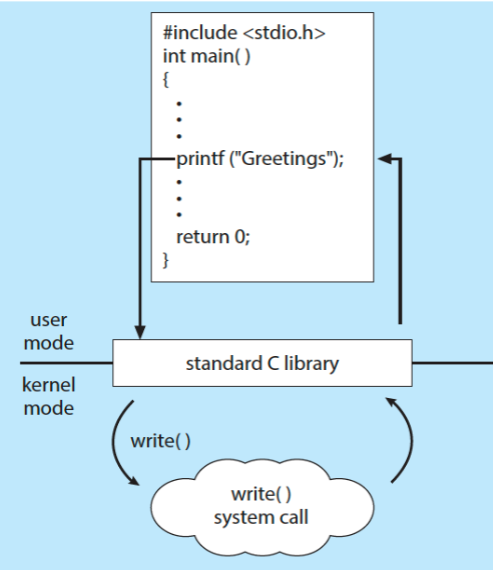
- leads to
- program invoking
- standard C library example
System Programs
-
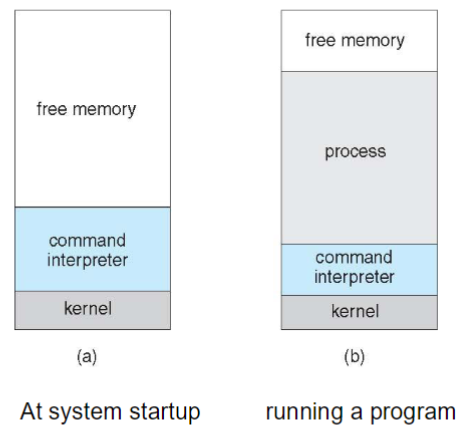
MS-DOS example
- characteristics
- single tasking
shellinvoked when system booted- simple to run a program
- no process created
- single memory space
- loads program into memory
- overwriting all: but the kernel
- program exit =>
shellreloaded
- characteristics
-
System programs
- another aspect of modern computer system: collection of system services
- system services: provide convenient environment for program development / execution
- aka system programs / utilities
- some: simply user interface to syscalls
- others: considerably more complex
- view of OS seen by most users: defined by application & system programs
- not the actual syscalls
- e.g. GUI featuring mouse-and-windows interface vs. UNIX shell
- same set of system calls
- yet, syscalls appear very differently & act in different way (from user)
-
List of system programs
- file management
- create, delete, copy, rename, print, dump, list
- and generally manipulate files & directories
- status information
- some: ask system for data, time, amount of available memory, disk space, number of users, etc.
- others: provide detailed performance, logging, debugging information
- file modification
- text editors to create & modify files
- special commands to search file contents / perform transformation of the text
- program-language support
- compilers, assemblers, debuggers, and interpreters
- for common programming languages (C, C++, Java, Python)
- often provided
- compilers, assemblers, debuggers, and interpreters
- program loading & execution
- absolute loaders, relocatable loaders, linkage editors, overlay-loaders, debugging systems
- for higher-level and machine language
- absolute loaders, relocatable loaders, linkage editors, overlay-loaders, debugging systems
- communications: providing mechanism for creating virtual connections
- among processes, users, and computer systems
- allowing users to:
- send messages to one another's screens
- browse web pages
- send electronic-mail messages
- log in remotely
- transfer files from one machine to another
- background services
- launch at boot time
- some: terminate after completing task
- some: continue to run until system terminates
- aka: services, subsystems, daemons
- provide: facilities like disk checking, process scheduling, error logging
- launch at boot time
- application programs
- not part of the OS
- launched by command line, mouse click, finger poke, etc.
- examples: web browsers, word processors, text formatters, spreadsheet, DB systems, games ...
- file management
-
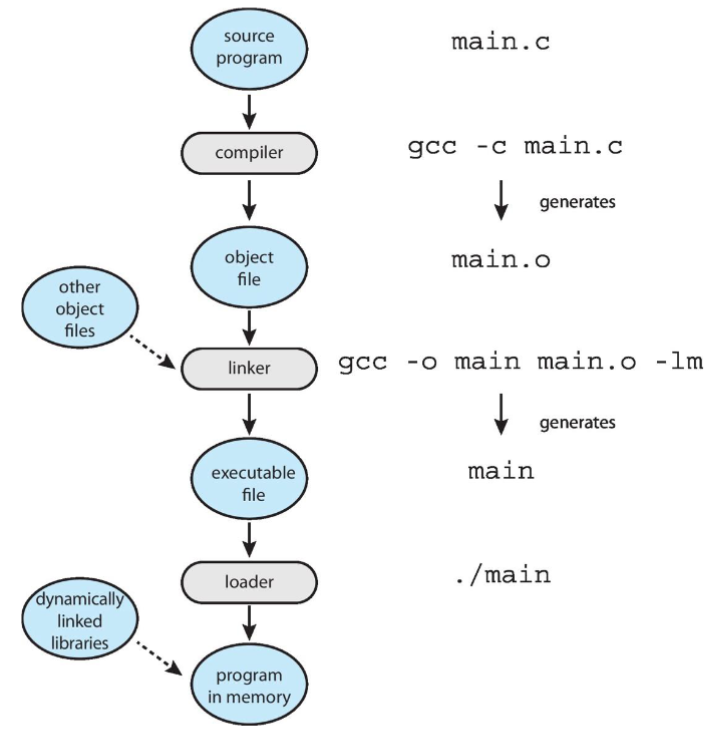
Linkers and loaders
- source codes: compiled into object files
- designed to be loaded into any physical memory location
- relocatable object files
- linker: combines object files into a single binary executable file
- programs: reside on secondary storage as binary executable
- must be brought into memory by loader to be executed
- relocation: assigns final addresses to program parts
- adjusts code & data in program to match those addresses
- modern general purpose OS: don't link libraries into executables statically
- instead: using dynamically linked libraries (aka DLLs in Windows)
- loaded when needed, and shared by all programs using the same version of that library
- loaded only once!
- loaded when needed, and shared by all programs using the same version of that library
- object files / executable files: often w/ standard formats
- machine codes, symbolic tables
- thus: OS knows how to load & start them
- instead: using dynamically linked libraries (aka DLLs in Windows)
- role of the linker and loader
- source codes: compiled into object files
Operating System Design and Implementation
-
Protection
- protection: internal problem
- security: considering both the system & surrounding environment of is
- OS: must protect itself from user programs
Reliability: compromising the OS: generally causes it to crashSecurity: limit the scope of what processes can doPrivacy: limit each process to the data it has access permissionFairness: each user / process: should be limited to its "appropriate share" of system resources
- system protection features: guided by
- principle of need-to-know
- implement mechanisms to enforce: principle of least privilege
- minimum possible permission to do the job!
- computer systems contain object that must be protected from misuse
- hardware: memory, CPU time, IO devices
- software: files, programs, semaphores
- protection: internal problem
COMP 3511: Lecture 5
Date: 2024-09-17 14:56:54
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Operating System Design and Implementation
-
Design and implementation of OS
- not solvable / no optimal solution
- characteristics
- internal structure: varies widely
- even at high level: design affected by choice of hardware / system type, etc.
- desktop / laptop / mobile / distributed / real- tie
- design: starts with specifying goals & specifications
- user goals: OS being convenient to use
- and ease to learn & use
- reliable, safe, fast
- system goals: easy to design, implement, and maintain
- and flexible, reliable (hopefully) error-free & efficient
- user goals: OS being convenient to use
- highly creative task of SWE
-
Important principle ⭐
- separation of policy & mechanism
- policy: what will be done
- mechanism: how to do it?
- e.g. time construct, mechanism for ensuring CPU protection
- deciding how long the timer will be: policy decision
- e.g. time construct, mechanism for ensuring CPU protection
- 👨🏫 policy: often changes
- separation of policy from mechanism: allows flexibility even policies change
- w/ proper separation: mechanism can be used to policy decision for
- prioritizing IO-intensive program
- as well as vice versa
- w/ proper separation: mechanism can be used to policy decision for
- OS: designed w/ specific goals in mind
- which: determine OS policies
- OS: implements policies through specific mechanisms
- separation of policy & mechanism
-
Implementation
- early OSes: written in assembly (~= 50 yrs a go)
- modern OS: written in higher level language
- for some special device/ function: assembly might still be used
- but general system: written in C/C++
- frameworks: in Java, mostly
- w/ higher level language: it can be easily ported
- also, code can be write faster, compact, and easier to maintain
- speed / increased storage requirement: not a concern now
- technology advances!
Operating System Structure
-
OS structure
- general purpose OS: very large program
- various ways to structure one
- monolithic structure
- layered - specific type of modular approach
- microkernel - mach OS
- loadable kernel modules (LKMs) - modular approach
-
Simple structure
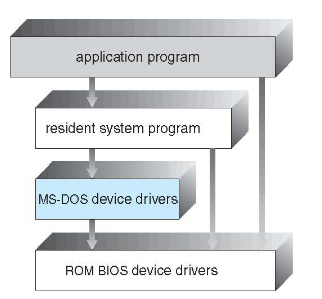
- the simplest possible
- structure not well-defined; started as a small / simple / limited system
- MS-DOS: written for maximum functionalist in minimum space
- not carefully divided into modules
- doesn't separate between user & os problem
- 👨🏫 NOT a dual system
- can cause many trouble nowadays (all user: can do sudo and all)
-
Monolithic structure: original linux
- kernel: consists of everything below the syscall interface
- and above the physical hardware
- employees multiprogramming
- 👨🏫 quite simple considering having to allocate stacks, etc.
- user: can't directly hardware
- kernel is underneath
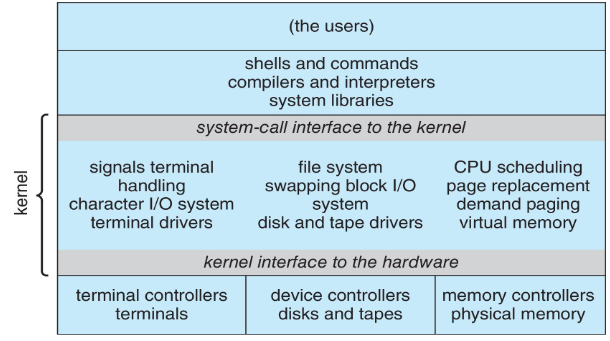
- UNIX: initially limited by hardware functionality => limited structuring
- 👨🏫 still, it is a single program!
- a single, static binary file running in a single address space
- monolithic structure!
- 👨🏫 still, it is a single program!
- UNIX: made of two separable parts
- kernel: further separated into interfaces & device drivers
- expanded as UNIX evolves
- system programs
- kernel: further separated into interfaces & device drivers
- drawback: enormous functionality: combined to one level
- difficult to implement, debug & maintain
- advantage: distinct performance!
- no need to pass parameter, etc.
- very little overhead in syscall interface and communication, etc.
- kernel: consists of everything below the syscall interface
-
Linux system structure
- i.e. modular design
- allows kernel to be modified during run time
- based on UNIT
- still, monolithic:runs entirely in kernel mode w/ single address space
- i.e. modular design
-
Modular design
- monolithic approach: too compact and tight interaction
- why not make the tie looser?
- so that change in one module / functionality does not affect the others parts!
- 👨🏫 ideally, and hopefully!
- one method: layered approach
- e.g. file system: located above hardware
-
Layered approach
- OS: divided into no. of layers
- each built on top of lower layers
- layer : hardware
- layer : user interface
- each layer: made of data structure & set of functions
- that can be invoked by higher level layers
- each layer: utilized the services from a lower layer, provides a set of functions
- and offers certain services for a higher layer
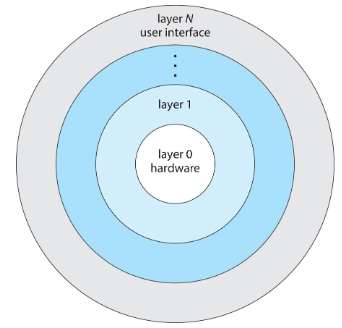
- 👨🎓 linux: all in 1 layer
- information higher: layer not needing to know lower-layer's implementation
- each layers: hides existence of its own data structures / operations to higher levels
- main advantage: simplification of construction & debugging
- layered system: successfully used in other areas too
- like TCP/IP vs. hardware (networking system)
- few systems tue pure layered approach though
- overall performance will be affected
- trend: fewer layers w/ more functionality & modularization
- while avoiding complex layer definition & interactions
- OS: divided into no. of layers
-
Mixed kernel system structure
- kernel: became large & difficult to manage
- some people: wanted to make OS a core
- and store all other nonessential parts outside
- mainstream (OS): expansion
- result: much smaller kernel
- Mach: developed at CMU in mid-1980s
- modularized the kernel w/ microkernel approach
- best-known microkernel OS: Darwin, used in Mac OS X, iOS
- consisting of 2 kernels, one being Mach microkernel
- UNIX / IBM, etc. thought it's desirable
- 👨🏫 but no general consensus on what's nonessential
- but generally: minimal process, memory management and communication facility: must be in kernel
- some of the essential functions
- provide communications between programs / services in user address space
- through message passing
- problem: if app wants to access file
- it must interact w/ file server through kernel, not directly to file / file manager
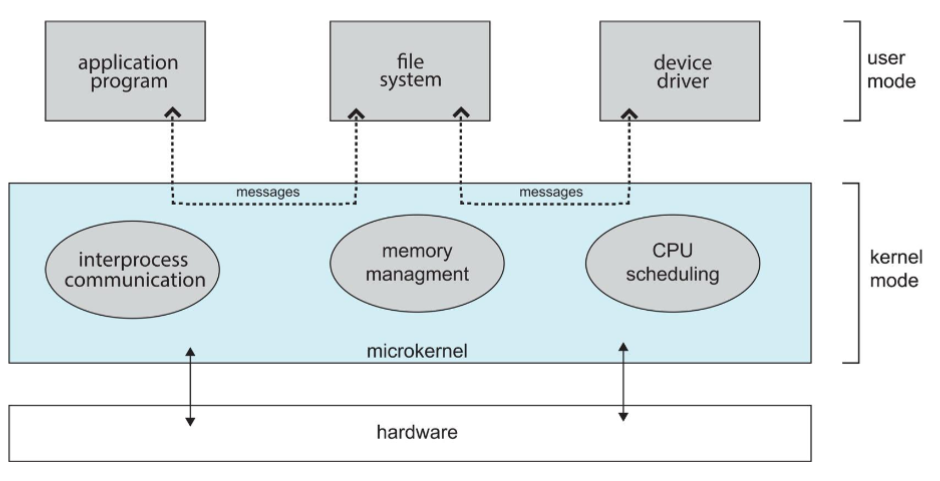
- provide communications between programs / services in user address space
- advantage
- easier to extend microkernel system (without modifying the kernel)
- minimal change to kernel
- easier to post OS to ner architectures
- more secure
- drawbacks: performance
- increased system overhead
- copying & storing messages during communication => makes it slow!
- not done by the mainstream
- Window NT: w/ layered microkernel
- much worse performance thantWindow 95 / Window XP
-
Modular approach: current methodology
- best current practice: involving loadable kernel modules (LKMs)
- i.e. programs can be added to kernel without rebooting
- once added, become a part of kernel, not user program!
- kernel: supports link to additional services
- services: can be implements & added dynamically while kernel is running
- dynamic linking: preferred to adding new features directly to kernel
- as it doesn't require recompiling kernel per every change
- resembles layer : as it has well-defined & protected interfaced
- yet, it's much more flexible
- also resembles microkernel: as primary module is only core functions and linkers
- more efficient that pure microkernel though
- linux: w/ LKMs, primarily for supporting device drivers & file systems
- LKMs: can be inserted into kernel during booting & runtime
- also can be removed during runtime!
- dynamic & modular kernel, while maintaining performance of monolithic system
- best current practice: involving loadable kernel modules (LKMs)
-
Case study: Solaris
- 👨🏫 in my days... Solaris was a dominant workstation provider
- PC wasn't a things... and we CS people used Linux
- now, the company is not computer system program though
- it worked with modular system
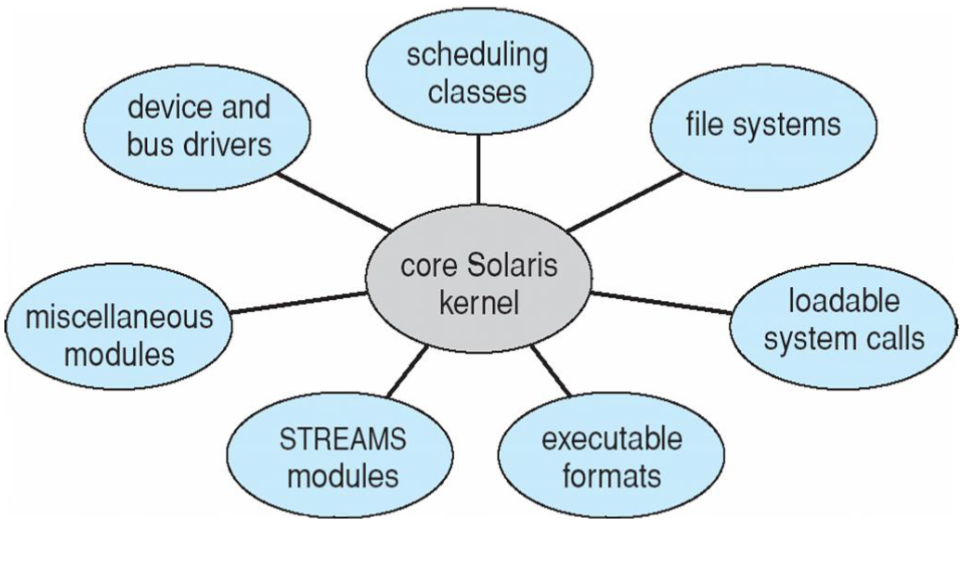
- 👨🏫 in my days... Solaris was a dominant workstation provider
-
Hybrid system
- most OS: combines benefit of different structures
- Linux: monolithic (in single address space), but also modular
- new functionality can be dynamically added
- windows: largely monolithic, with some microkernel behavior
- also provide support for dynamically loadable kernel modules
-
macOS & iOS structure
- in architecture: mcOS & iOS: have much in common
- UI, programming support, graphics, media, and even kernel environment
- Darwin: includes Mach microkernel and BSD UNIX kernel
- with dual base programs
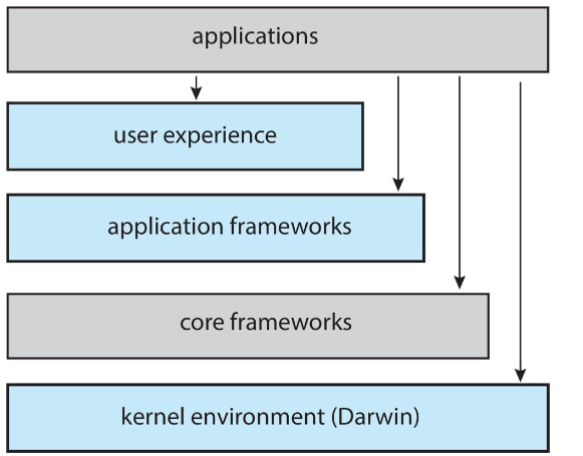
- higher level structure
- Max OS X: hybrid, layered, Aqua UI (mouse / trackpad)
- w/ Cocoa programming environment: API for Objective-C
- core frameworks: support graphics and media
- including Quicktime & OpenGL
- kernel environment (Darwin) includes Mach microkernel & BSD
- iOS
- structured on Mac OS; added C functionality
- does not run applications natively; runs on different CPU architectures too (ARM & Intel)
- core OS: based on Mac OS X kernel, but with optimized battery

- Springboard UI: designed for touch devices
- Cocoa Touch: Object-C API for mobile app development (touch screen)
- Media services: layer for graphics, audio, video, quicktime, OpenGL
- Core services: providing cloud computing & data bases
- Core OS: based on Max OS X kernel
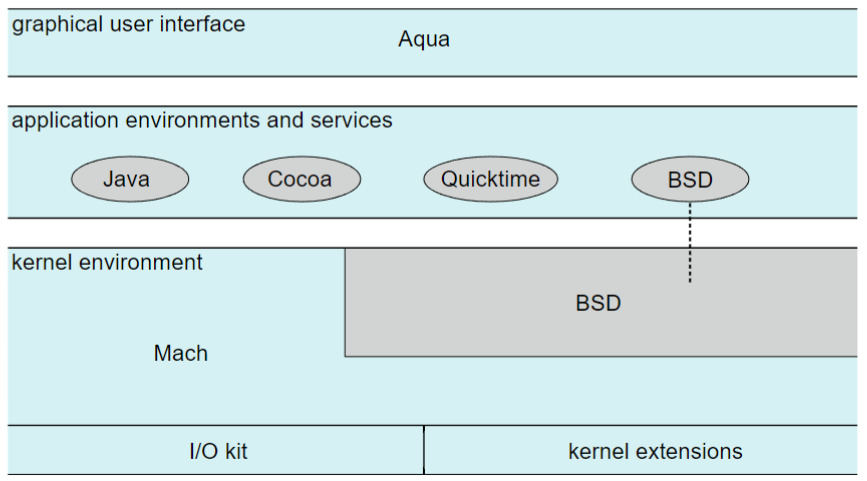
- Darwin
- layered system consisting of Mach microkernel & BSD UNIX kernel
- hybrid system
- two syscall interfaces: Mach syscalls (aka traps) and BSD syscalls (POSIX functionality)
- interface: rich set of libraries - standard C, networking, security, programming languages..
- Mach: providing fundamental OS services
- memory management, CPU scheduling, IPC facilities
- kernel: provide IO kit for device drivers
- dynamically loadable modules: aka kernel extensions (kexts)
- BSD: THE first implementation supporting TCP/IP, etc.
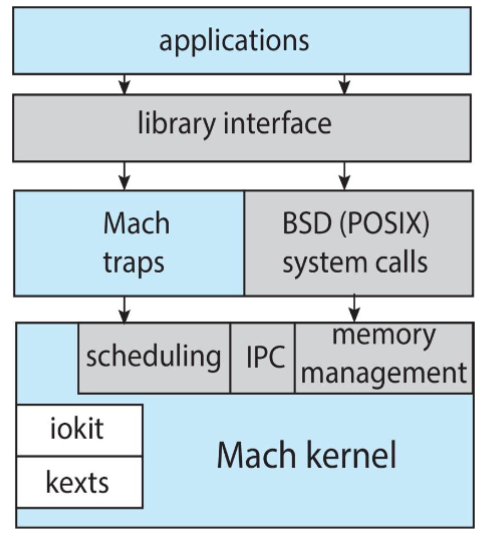
- layered system consisting of Mach microkernel & BSD UNIX kernel
- in architecture: mcOS & iOS: have much in common
-
Android
- developed by Open Handset Alliance (led by GOogle)
- runs on a variety of mobile platforms
- open-source, unlike Apple's closed-sources
- similar to OS: layered system providing rich set of frameworks
- for graphics, audio, and hardware
- using a separate Android API for Java development (not standard Java)
- Java app: execute on Android Run Time (ART)
- VM: optimized for mobile devices w/ limited memory & CPU
- Java native interface (JNI): allows developers to bypass CM
- and access: specific hardware features
- programs written in JNI: generally not portable in terms of hardware
- libraries: include framework for:
Webkit: web browser devSQLite: DB supportSSLs: network support (secure sockets)
- hardware abstract layer (HAL): abstracts all hardware
- providing applications w/ consistent view
- independent of hardware
- providing applications w/ consistent view
- uses Bionic standard C library by google, instead of GNU C library for Linux systems
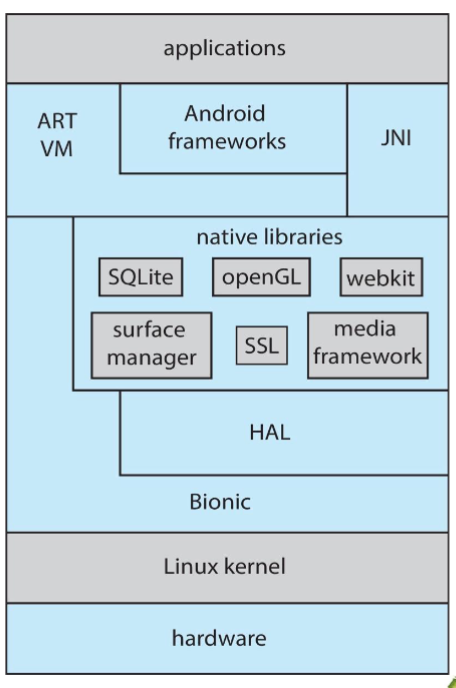
Process: Introduction
-
Introduction to processes
- 👨🏫 a real thing! no more high level!
- objectives:
- identify components of process, representation, and scheduling
- describe creation & termination using appropriate syscalls
- describe and contrast inter-process communication w/ shared memory
- and message passing methods
-
Four fundamental OS concepts
- process
- instance of an executing program
- made of address space & more than 1 thread of control
- thread (continues in Ch. 4)
- single unique execution context
- full description of program stated
- captured by program counter, registers, execution flags, and stack
- for parallel operations..?
- address space (w/ address translation)
- programs: execute in address space
- != memory space of physical machine
- each program: starts w/ address 0
- programs: execute in address space
- dual mode operation (= Basic protection)
- user program / kernel: runs in different modes
- different permissions per programs
- OS & hardware: protected from user programs
- user programs: protected & isolated from one another
- process
Process concept
-
Process concept
- OS: executes a variety of programs: each runs as process
- process: captures a program execution, in a sequential manner
- von Neumann architecture
- process: contains multiple parts
- program code: aka text section
- current activities or state: program counter / processor registers
- stack: temporary data storage when invoking functions
- e.g. for function parameters, return addresses, etc.
- data section: containing global variables
- heap: w/ dynamically allocated memory during run time
- 👨🏫 stack & heap can grow dynamically: during execution
- program: passively stored on disk
- process: active entity, w/ PC specifying next instruction to fetch & execute
- process: with life cycle: from execution to termination
- program: becomes a process
- when executable file is loaded into main memory & get ready to run
- executes in address space, different from actual main memory location
- one program: can be executed by multiple processes
- a program: can be an execution environment for others (e.g. JVM)
-
Loading program into memory
- program: must be loaded to memory before execution
- load its code & static data into memory / address space
- some memory: allocated for program's runtime stack
- for C: stack used for local variables, function parameters, return addresses
- fill in: parameters for
main(): e.g.argc,argv
- OS: may allocate memory for program's heap
- programs: request & returns it explicitly
- dO: also d some initialization tasks
- esp. relating to IO
- e.g. UNIX: each process w/ 3 open file descriptors
- standard input / output / error
- esp. relating to IO
-
Memory layout of a program
- global data: divided into initialized data and uninitialized data
- separate section for
argc,argvparameters 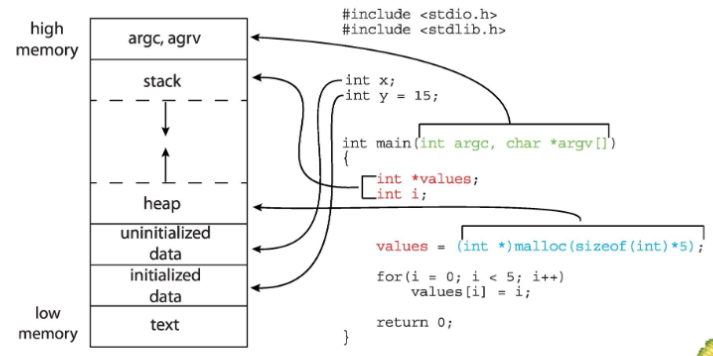
COMP 3511: Lecture 6
Date: 2024-09-19 14:59:46
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Process Concept (cont.)
-
Process state
- traditional Unix: each process = 1 thread
- process state current activity of that process
- as process executes: it changes states
- new: process being created / allocating resource
- ready: process waiting to be assigned to CPU
- 👨🏫 remember ready queue and CPU core!
- running: instructions being fetched & executed
- waiting: process waiting for event to occur
- terminated: process finished execution / deallocating resource
- ❓ how do process manager work? how much CPU resource does it take?
- 👨🏫 will be discussed later (whole chapter)
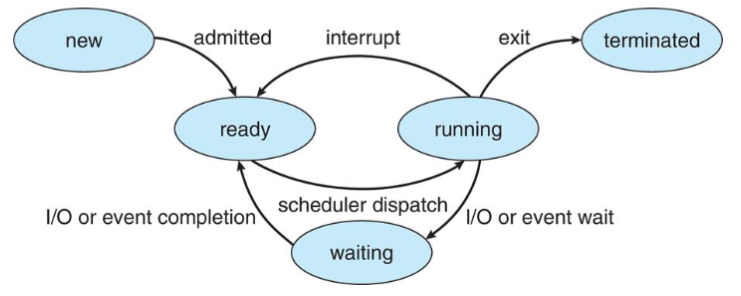
- different things might happen in running state
exit: finished all tasksinterrupt: after each line of instruction: checks interrupt signal- if detected: add interrupt routine to process queue
I/O || event: I/O service, etc: are much slower than CPU- so the process gives up CPU itself, and waits for signal (from IO / etc.)
- traditional Unix: each process = 1 thread
-
Process control block (PCB)
- each process: corresponds to 1 PCB
- i.e. info. associated w/ each process
- aka: task control block
- includes following info:
process state: running / waiting, etc.program counter: location of instruction to be fetched nextCPU registers: accumulators, index resisters, stack pointers, general-purpose registers, condition-code informationCPU scheduling info.: priorities, pointers to scheduling queue, scheduling parametersmemory-management info.: memory allocated to the process- complicated data structure: paging & segmentation tables
- 👨🏫 for now, consider it as a pointer to program data structure
- 👨🏫 program: simple binary; process: dynamic!
accounting info.: CPU used, clock time elapsed, time limits- simple statistics
IO status info.: IO devices allocated to process- e.g. list of open files

- each process: corresponds to 1 PCB
-
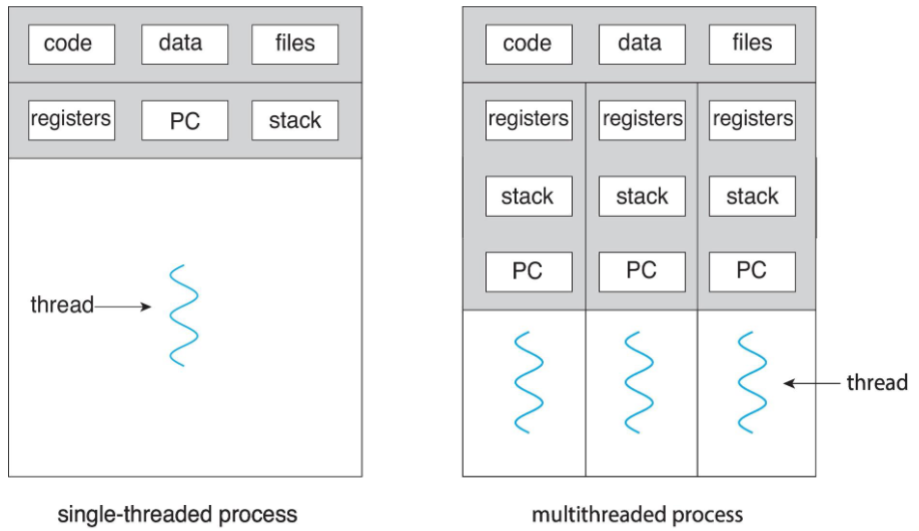
Threads
- we assumed: a process w/ single thread of execution
- thread: represented by: PC, registers, execution flags, stack
- modern OS: allow a process w/ multiple threads
- thus can perform parallel execution
- e.g. browsers: contacting web server vs. displaying image, etc.
- w/ multi-core systems: multiple threads of process: can run in parallel
- process: can consist of 1 / multiple threads
- running within the same address space (e.g. sharing code & data)
- each thread: w/ its own, unique state
- multi-threads: process providing concurrency & active components
- we assumed: a process w/ single thread of execution
-
Process representation in Linux
- Linux: storing list of processes in circular doubly LL
- aka task list
- each element in task list: of type struct
task_struct- i.e. PCB
pid t_pid; long state; unsigned int time_slice; struct task_struct *parent /* TBD */ struct list_head children /* TBD */ struct files_struct *files /* TBD */ struct task_struct *parent /* TBD */ - Linux: storing list of processes in circular doubly LL
Process Scheduling
-
Process schedule
- primary object of multiprogramming: keep CPU busy
- as it's a scars resource
- process scheduler: OS mechanism selecting a process
- from available processes inside main memory
- scheduling criteria: CPU utilization, job response time, fairness, real-time guarantee, latency optimization...
- degree of multiprogramming: no. of processes currently residing in memory
- determines resource consumption
- processes: roughly either:
- I/O bound process: spends more time w/ IO than computations
- many short CPU bursts
- CPU bound process: generates IO requests infrequently
- more time doing computations; few, very long CPU bursts
- I/O bound process: spends more time w/ IO than computations
- primary object of multiprogramming: keep CPU busy
-
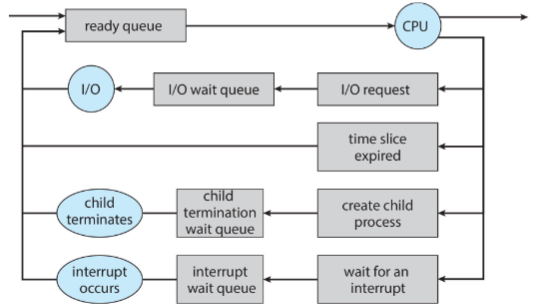
Scheduling queue
- OS: maintains different scheduling queues of processes
- ready queue: set of processes in main memory;
- ready & waiting to execute
- wait queue: set of processes waiting for an event
- ready queue: set of processes in main memory;
- processes: migrate among various queues during lifetime
- OS: maintains different scheduling queues of processes
-
Representation of process scheduling
-
Schedulers
- long-term scheduler (job scheduler)
- for scientific & heavy computation
- selects which processes to be brought to memory
- for mainframe minicomputers (not PC)
- made of job queue: hosts job submitted to mainframe computers
- short-term scheduler (CPU scheduler)
- selects a process from a ready queue to be executed next & allocate CPU for it
- short-term scheduler: invoked frequently (μs, must be fast)
- long-term scheduler: invoked infrequently (s,min, may be slow)
- long term scheduler: dictates degree of multiprogramming
- mainframe computer system:
- long-term scheduler (job scheduler)
-
Medium term scheduling
- if you underestimated the program resource:
- swap out (not terminating) some programs
- entire process information (not just PCB)
- and use the freed up resource to accelerate & give more space
- swap out (not terminating) some programs
- for PC: you can simply kill the resources
- for mainstream: it's all services that's paid
- mostly not implemented for PC
- if you underestimated the program resource:
-
Inter-process CPU switch
- context switch: when CPU switches from one process to another
- sample OS task
- save state into PCB-0
- reload state from PCB-1
- save state into PCB-1
- reload from PCB-0
- ...
- sample OS task
- context: must be saved (in PCB / in each thread of process)
- typically: including registers, PC, stack pointer
- context-switch time: an overhead
- system: doesn't do useful work during it
- takes longer if OS & PCBs are complex
- switching speed: depends on
- memory speed
- no. of registers copied
- existence of a special instructions to load & store all registers
- speed: highly dependent on underlying hardware
- e.g. some processors: provide multiple sets of registers
- context switch: simply changing the pointer to a different register set
- context switch: when CPU switches from one process to another
Dual-mode Operation
-
Dual mode operation
- allows OS to protect itself & other system components
- 👨🏫 MS-DOS didn't have it; Windows have
- user mode: has less access / permission to hardware than the kernel mode
- can be easily extended to multiple modes!
- ❓ sudo = executing as the lowermost user?
- dual-mode operation provides: basic means of OS protection & users
- from errant / bad users
- all access: must be strictly controlled by well-defined OS API
- switching between modes: constant
- e.g. (user) API call to open -> (kernel) open -> (user) displays
-
Three types of mode transfer
- 3 common ways to access kernel mode from user mode
- system call:
- interrupt:
- trap / exception:
Operations on Processes
-
Operations on processes
- processes in most systems: execute concurrently;
- created & deleted dynamically; thus OS must support
- process creation: running a new program
- process termination: program execute completes / terminate
- parent process: can create children processes
- children: can create other child processes
- tree of processes!
- 👨🏫 shell: also a process!
- waiting for your input
- all commands running on it: children process of shell
desktop: can be a parent process- process started on it (e.g. by double click): its children process
- the grandpa:
rootprocess
-
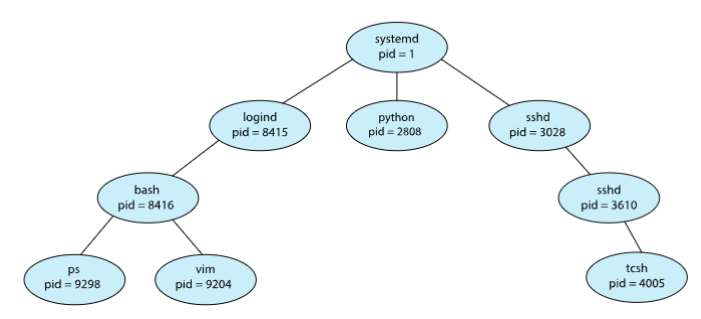
Tree of processes on Linux system
-
Process creation
- most OS: identify process according to unique process identifier
- or:
pid, usually an integer
- or:
- child process: needs certain resources
- CPU time, memory, files, IO devices to accomplish task
- parent process: also pass along initialization dat (input)
- to child process
- parent & children: share "almost" all resources
- three choices possible on how to share the resource
- parent & children: share almost all resources:
fork() - children: share only subset of parent's resources:
clone() - parent & children: share no resources
- parent & children: share almost all resources:
- two options for execution after process creation
- parent: continues to execute concurrently with its children
- parent: wait until some / all its children to terminate
- again, two choices of address space for a new child process
- child process: duplicates of parent (same program & data) - Unix/Linux
- child process: has a new program loaded into it (different program & data) - Windows
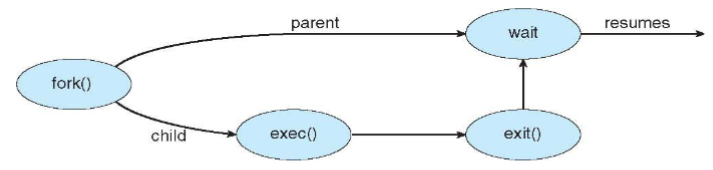
- UNIX examples
fork(): creates a new process; duplicates entire address space of the parent- both processes: continue execution at the next instruction after
fork()
- both processes: continue execution at the next instruction after
exec(): maybe used afterfork(): to replace child process's address space w/ a new program- loading a new program
- parent: can call
wait()to wait for a child to finish
- most OS: identify process according to unique process identifier
COMP 3511: Lecture 7
Date: 2024-09-24 14:35:41
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Operation on Processes (cont.)
-
Process creation
-
fork()
- parent & child: can be added to ready queue parallelly
- behavior: cannot be determined by code only
- parent & child: resumes execution after
forkw/ the same PC- i.e. the return of
fork()call
- i.e. the return of
- after
- return values of
fork()- each process: receives exactly one return value
-1: unsuccessful (to parent)0: successful (to child)>0: successful (to parent)- returned value: child's PID
- 👨🏫 losing track of PID / etc.: not discussed here
- 👨🏫 this value: used to distinguish post-fork behavior of process
- almost everything of the parent gets copied
- memory / file descriptors / etc.
- i.e. such copy of everything: very costly & time consuming
- parent can't access child's cloned memory
- nor the child access parent's original memory
- parent & child: can be added to ready queue parallelly
-
UNIX fork
- create & initialize process control block (PCB) in kernel
- create new address space / allocate memory
- initialize address space w/ the copy of entire contents
- time consuming!
- inherit the execution context of the parent (e.g. open files)
- i.e. all stack and etc. information
- inform the CPU scheduler: child process is ready to run
-
parent & child comparison
- after
fork()
Duplicated Different address space PID global-local var fork()returncurrent working dir running time root dir running state process resources resource limits program counter ... example
#include <stdlib.h> #include <stdio.h> #include <string.h> #include <unistd.h> #include <sys/types.h> #define BUFSIZE 1024 int main(int argc, char *argv[]) { char bug[BUFSIZE]; size_t readlen, writelen, slen; pid_t cpid, mypid; pit_t pid = getpid(); printf("Parent pid: %d\n", pid); cpid = fork(); // branch if (cpid > 0) { mypid = getpid(); // parent printf("[%d] parent of [%d]\n", mypid, cpid); } else if (cpid == 0) { mypid = getpid(); // child printf("[%d] child\n", mypid); } else { perror("Fork failed"); exit(1); } }- note that
- output after printing (i.e. within control flow) has undetermined order
- depending on CPU scheduler
- output after printing (i.e. within control flow) has undetermined order
- after
-
-
system calls
-
exec(), execlp(): syscall to change program in current process- creates a new process image from: regular executable file
- 👨🎓 ~=
jto another program?- ⭐ no return to original process!
-
wait(): syscall to wait for child process to finish- or: on general wait for event
- 👨🏫 enter waiting stage & give up CPU
- 👨🎓 if parent keep occupying CPU: then a single-core won't be able to be execute a fork w/
wait() - ⭐ very very important!
- 👨🎓 if parent keep occupying CPU: then a single-core won't be able to be execute a fork w/
-
exit(): syscall to terminate current process-
- free all resources
-
-
signal(): syscall to send notification to another process -
implementing a shell
char *prog, **args; int child_pid; while (readAndParseCmdLine(&prog, &args)) { child_pid = fork(); if (child_pid == 0) { exec(prog, args); // run command in child // cannot be reached } else { wait(child_pid); return 0; } } -
fork tracing
- to trace forks in loops, try to expand the loop
- e.g.
for (int i=0; i < 10; ++i) fork();intofork(); fork(); fork();...
- e.g.
fork diagrams (credit: IA Peter)
- to trace forks in loops, try to expand the loop
-
---
title: fork()
---
flowchart LR
p0((p0)) --> f1{fork 1}
f1 --> p0_2((p0))
f1 --0--> p1((p1))
---
title: fork(); fork()
---
flowchart LR
p0((p0)) --> f1{fork 1}
f1 --> p0_2((p0))
f1 --0--> p1((p1))
p0_2 --> f2{fork 2}
f2 --> p0_3((p0))
f2 --0--> p2((p2))
p1 --> f3{fork 3}
f3 --> p1_2((p1))
f3 --0--> p3((p3))
---
title: fork()&&fork()
---
flowchart LR
p0((p0)) --> f1{fork 1}
f1 --> p0_2((p0))
f1 --0--> p1((p1))
p0_2 --> f2{fork 2}
f2 --> p0_3((p0))
f2 --0--> p2((p2))
---
title: fork()||fork()
---
flowchart LR
p0((p0)) --> f1{fork 1}
f1 --> p0_2((p0))
f1 --0--> p1((p1))
p1 --> f2{fork 2}
f2 --> p1_2((p1))
f2 --0--> p2((p2))
</details>
-
Final notes on fork
- process creation is unix: unique (no pun)
- most os: create a process in new address space & read in an executable file and execute
- Unix: separating it into
fork()andexec()
- linux:
fork(): implemented viacopy-on-write- as usually: we don't need the entire copy
- thus we can delay / prevent copying the data
- until content is changes / written to
- improves speed a lot!
- thus we can delay / prevent copying the data
- child process: points to parent process's address space
- as usually: we don't need the entire copy
- linux also implements
fork()viaclone()(more general)clone(): uses a series of flags allow to specify which set of resources should be shared by parent & child
- process creation is unix: unique (no pun)
-
Process termination
- termination
- after process executes the last statement
exitsyscall: used to ask OS to delete it
- after process executes the last statement
- some os: do not allow child to exist if parent has terminated
- i.e. all children are to be terminated after parents
- cascading termination by the OS
- i.e. all children are to be terminated after parents
- process termination:
- deallocation: must involve the OS
- e.g. kernel data, etc.: cannot be accessed / modified by the user application
- concepts
- zombie process: process terminated, but
waitnot called on parents yet- e.g. corresponding entry in the process table / PID, and PCB
- 👨🏫 every process enters this stage, at least for a moment after termination
- nothing wrong. It's just "we are almost over"
- but zombies can be accumulated, and wit as a problem back then
- because the memory restriction was very tight ~=30 years ago
- once parent calls wait:
PIDof zombie process and other corresponding entry: released - such design: enables parent inform the OS termination of the child
- 👨🏫 not the best design, nor the only. but the design of Unix
- if parent terminates without invoking
wait()- child becomes an orphan
- without cascading, the process might be still runnable
- or become a zombie
- which, will never be released, as no parent exist
- thus: all process (except root or so): must have a parent
- (or kill them all using cascading)
- 👨🎓 can we assign
- 👨🏫 this is the design chosen by UNIX
- 👨🎓 can't we ensure the child to call OS and take care of themselves?
- maybe we can, but this is choice or trade-off made by the unix
- 👨🏫&👨🎓 parent has ability to track all its children, but it is not required.
- 👨🎓 can't we ensure the child to call OS and take care of themselves?
- zombie process: process terminated, but
- termination
COMP 3511: Lecture 8
Date: 2024-09-26 15:11:13
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Communication
-
General
-
Communication models
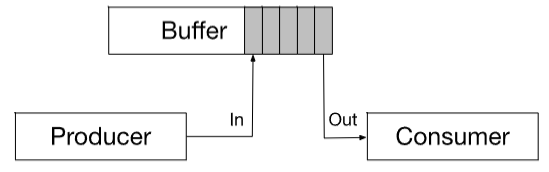
- producer-consumer problem
- represents common type of inter-process cooperation
- producer: produces information (& puts into buffer)
- consumer: consumes information (e.g. display)
- unbounded buffer: places no practical limit on the size of the buffer
- bounded buffer: assumes: fixed puffer size
- producer-consumer problem
-
Shared memory
-
shared data
- bounded buffer: pseudocode
#define BUFFER_SIZE 10 typedef struct { ... } item; item buffer[BUFFER_SIZE]; int in = 0; int out = 0; - allows at most
BUFFER_SIZE-1items in buffer at same time- "one" of the common communication method
- different implementations: can use all
BUFFER_SIZEitems
Pseudocode
s - bounded buffer: pseudocode
-
-
Message passing
- mechanism for communication & synchronization
- without sharing the same address
- particularly useful: in distributed environment
- IPC facility: provides
send (message)receive (message)
- message size: can be either fixed / variable
- in order to processes to communicate, they need to
- establish a communication link between them
- 👨🏫 need to know somehow each other's identity!
- such processes can eue either direct / indirect communication
- exchange messages visa primitives:
send(),receive()
- establish a communication link between them
- different methods exist
-
Direct communication
- processes: must name each other explicitly
- usually: PID, but can be acronyms, etc.
send(P,m)
- d
- processes: must name each other explicitly
-
Indirect Communication
- messages: sent to and received from mailboxes
- each mailbox: w/ unique id
- processes: can communicate only if they share a mailbox
- properties of communication link
- link: established written a pair of processes
- only if both members of pair: w/ shared mailbox
- d
- link: established written a pair of processes
- basic mechanism to support:
- create a new mailbox
- send & receive messages through the mailbox
- destroy the mailbox
- primitives: defined as
send(A,message): send message to mailbox:send(A,message): receive message from mailbox:
- mailbox sharing
- : shares mailbox
- can receive message from ?
-
solutions
- messages: sent to and received from mailboxes
-
Synchronization
- message passing: either blocking / non-blocking
- or: synchronous - asynchronous
- 4 possibilities
- status of sender & receiver
- blocking: considered synchronous
- blocking send: sending process: blocked until message is received
- i.e. I'll until you confirm
- blocking receive: receiver blocks until a message is available
- i.e. give me message! give me message! give me message!
- blocking send: sending process: blocked until message is received
- non-blocking: considered asynchronous
- non-blocking send: sending process: sends message & resumes operation
- not waiting for message reception
- non-blocking receive: receiver: retrieve either a valid message / null
- rendezvous: when
send()andreceive()are both blocking- i.e. common place
- pseudocode
- producer-consumer: becomes trivial
- message passing: either blocking / non-blocking
-
Buffering
- either direct / indirect, messages exchange by communicating processes reside in a temporary queue
- queue: either in three ways
- zero capacity: no messages are queued on a link
- sender: must wait for receiver
- zero capacity: no messages are queued on a link
- sender: must wait if link is full
- unbounded capacity: infinite length
- sender never waits
- zero capacity: no messages are queued on a link
-
Pipes
- piped: one of the first IPC mechanism in early UNIX systems
- is communication: unidirectional / bidirectional?
- must there exists a relationship between processes?
- e.g. parent-child
- can the pipes:used over a network?
- or only on the same machine?
- ordinary pipes: cannot be accessed from outside the process that created it
- typically: parent process creates a pipe
- and uses it to communicate with child, made by
fork()
- names pipes: can be accessed without a parent-child relationship
- destroyed by the OS upon process termination
- piped: one of the first IPC mechanism in early UNIX systems
-
Ordinary pipes
- communicates in a standard producer-consumer fashion
pipe(int fd[])in unix: unidirectional- producer: writes to one end (write end,
fd[1]) - producer: reads from end (read end,
fd[0])
- producer: writes to one end (write end,
- requires parent-child relationship
- cannot be accessed from outside the process created them
- cease to exist after processes finish communication & terminated
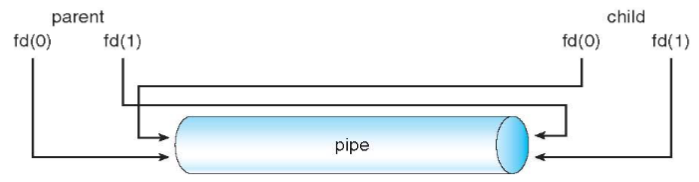
- unix: treats pipe as a special type of file
- standard
read(),write(), and the child: inherits pipe from parent process - parent process: use
pipe()to create pipe- then use
forkto create a child process- child: inherits pipe as well
- 👨🏫 inherited fo one child only, in original UNIX
- then use
- standard
- example code
-
Names pipes
- more powerful than ordinary pipes!
- bidirectional
- no parent-child relationship required
- multiple process can use it (w/ several writers)
- names pipes: continues to exist after processes terminate
- must be explicitly deleted
- names
- more powerful than ordinary pipes!
-
Client-server communication
- sockets
- defined as: endpoint for communication
- pair of process communicating over a network:
- employs a pair of socket
- uniquely identified by an IP address and a port number
- port: specifies process / application on client / server side
- server: waits for incoming client requests
- by listening to a specified port (well-knowns)
- once received: server can choose to accept the request
- to establish a socket connection
- port number: different for different process
- although they are the same application
- e.g. two tabs of chrome browser: separate process & separate port number!
- defined as: endpoint for communication
- remote procedure calls (RPC)
- one of the most common forms of remote services
- procedure-call mechanism: for use between systems w/ network connections
- RPC: commonly used for implementing distributed file systems
- one of the most common forms of remote services
- sockets
-
Sockets
- servers: listen to well-known ports (SSH-22; FTP-21; HTTP-80)
- all ports below 1024: well-known and reserved for standard services
- server: always running & with well-known IP address & IP
- only client: can initialize communication
- when client initiate a request:
- it should know its OP address
- and select a client port number not in use ()
- 4-tuple: uniquely determines a pair of communication
- source IP address
- source port number
- destination IP address
- destination port number
- 👨🏫 even only 1/4 are different: they are different pair!
- ⭐⭐ requirements for communication to occur
- server: MUST BE ALWAYS RUNNING
- server address & port: MUST BE KNOWN
- server side port: the same
- HTTP:
80
- HTTP:
- IP address: known by domain naming system (DNS)
- original idea: having a gigantic machine with single IP address
- however: cannot handle world-size traffic like Google
- professor: has a 1999 paper on how to allocate replica
- which server to access (i.e. nearby / quickest)
- which IP to access (relating to DNS)
- server side port: the same
- servers: listen to well-known ports (SSH-22; FTP-21; HTTP-80)
COMP 3511: Lecture 9
Date: 2024-10-03 15:02:14
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Multi-Threads Basics
-
Thread
- many app / programs: multithreads
- e.g. web browser: some displaying images, some retrieving data from internet
- or: each tabs in a browser
- to perform tasks efficiently
- e.g. web browser: some displaying images, some retrieving data from internet
- most OS kernels: multithreads
- e.g. multiple kernel threads created Linux system boot time
- motivation: can take advantage of processing capabilities on multicore systems
- i.e. parallel programming: often in data mining, graphics, AI
- process creation: time consuming and resource intensive
- thread creation: light-weight
- as thread shares code, data, and others within the process
- many app / programs: multithreads
-
Multithreaded program examples
- embedded systems
- elevators, planes, medical systems, etc.
- single program on concurrent operations
- most modern OS kernels
- internally concurrent: to deal w/ concurrent requests by multiple users
- no internal protection needed in kernel
- DB servers
- access to shared data of many current users
- background utility processing: must be done
- network servers
- concurrent requests from network
- file server / web server / airline reservation systems
- parallel programming
- split program & data into multiple threads for parallelism
- embedded systems
-
Single & multithreaded processes
- thread: basic unit of CPU utilization
- independently scheduled & run - instance of execution
- represented by
- thread ID
- program counter
- register set
- stack
- shares code, data, and OS resources: e.g. open files & signals
- efficiency: depends on no. of cores allocated to the process
- benefits
- responsiveness
- resource sharing
- threads: share process resource by default
- easier than inter-process shared memory / message passing
- as: threads run within the same address space
- economy
- thread creation: cheaper than process creation
- context switch: faster intra-process (thread) than inter-process
- scalability
- processes: can take advantage of multicore architecture
- thread: basic unit of CPU utilization
Multicore & Parallelism
-
Multicore design
- multithreaded programming: provides mechanism for more eff. use of multi-cores
- and improves concurrency in multicore systems
- ⭐👨🏫 L2 cache / memory are shared by cores
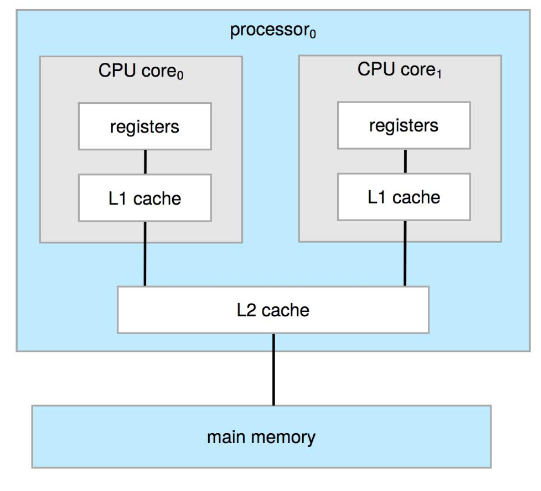
- multithreaded programming: provides mechanism for more eff. use of multi-cores
-
Multicore programming
- significant new challenges in multicore/multiprocess programming design
- dividing tasks: how to divide into separate / concurrent tasks
- balance: each task performing equal amount of work
- data splitting: data used by tasks: divided to run on separate cores
- 👨🎓 dividing seed among farmers to work concurrently
- data dependency: synchronization required if data dependency exist
- e.g. operation B: requiring completion of operation A
- testing and debuggingL different path of executions: makes debugging difficult
- parallelism != concurrency
- parallelism: system can perform more than one task simultaneously
- concurrency: supporting more than one task for making progress
- i.e. doing more than one job over a time
- when multiplexed over time: single process core, scheduler provides concurrency
- advent of multicore: requires new approach in software system design
- significant new challenges in multicore/multiprocess programming design
-
Concurrency vs. parallelism
- concurrent: single core multiplexing over time
- parallel: execution on a multi-core system
- 👨🏫 rigorously, parallelism only exists in multicore
- but many literatures don't differentiate them
- concurrent: single core multiplexing over time
-
Data & task parallelism
- data parallelism: distribute subset of data across multiple cores
- same operation on each core
- common: in distributed machine learning tasks
- task parallelism: distribute: threads across core
- each thread: performing unique operation
- data & task: not mutually exclusive: could be used at the same time!
- data parallelism: distribute subset of data across multiple cores
-
Amdahl's law
- designs performance gain from additional cores to an application
- w/ both serial and parallel components
- : serial portion
- : parallel portion
- : processing cores
- speedup
- as approaches infinity: speedup approaches
- serial portion of application: disproportionate effect
- on performance gained by adding additional cores
- e.g. if application if 75% parallel, 25% serial
- then moving from 1 to 2 cores: give speedup of
- 👨🏫 even if you have 5% of serial portion: speedup decreases significantly
- designs performance gain from additional cores to an application

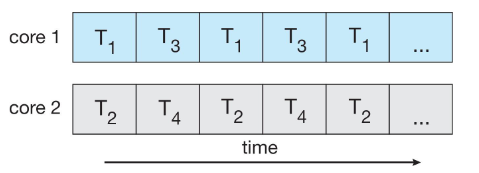
Threads
-
Multithreaded processes
- multithreaded process: more than one instance of execution (i.e. threads)
- thread: similar to process, but shares the same address space
- state of each thread: similar to process
- with its of program counter and private set of register for execution
- two thread running on single process: switching from threads requires context switch, too
- register state of a thread: saved, and another thread's is loaded / restored
- address space: remains the same - much smaller context switch
- and thus much small overhead
- thus parallelism is supported
- enables overlap of IO with other each activities within a single program
- one thread: running on CPU; another thread doing IO
-
Thread
- thread: single unique execution context: lightweight process
- program counter, registers, execution flags, stack
- thread: executing on processor when it resides i registers
- PC register: holds address of currently executing instruction
- register: holds root state of the thread (other state in memory)
- each thread: w/ thread control block (TCB)
- execution state: CPU registers, program counter, pointer to stack
- scheduling info: state, priority CPU time
- accounting info
- various pointers: for implementing scheduling queues
- pointer to enclosing process: PCB of belonging process
- thread: single unique execution context: lightweight process
-
Thread state
- thread: encapsulates concurrency - active component of a process
- address space: encapsulates protection - passive part of process
- one program's address space: different from another's
- i.e. keeping buggy program from thrashing entire system
- state shared by all threads in a process / address space
- contents onf emory (global variables, heap)
- IO state (file descriptors, network connections, etc.)
- state not shared / private to each thread
- kept in TCB: thread control block
- CPU registers (including PC)
- execution stack: parameters, temporary variables, PC saved
-
Lifecycle of a thread
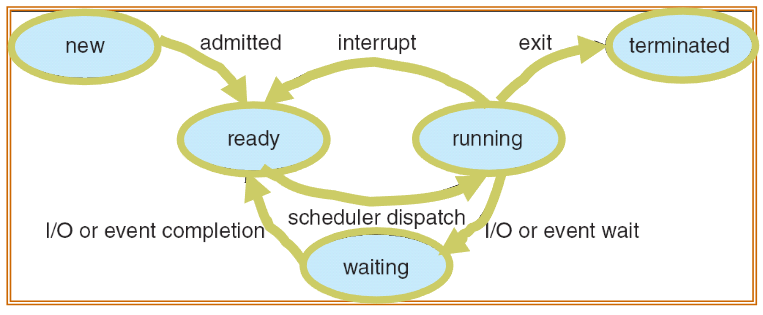
- change of state
new: thread being createdreadythread waiting to runrunning: instructions being executedwaiting: thread waiting for event to occurterminated: thread finished execution- or: killed by OS / user
- active threads: represented by TCBs
- TCBs: organized into queues based on states
-
Ready queue and IO device queues
- thread not running: TCB is in some queue
- queue for each device / signal / condition: w/ their own scheduling policy
- more accurate visualization of ready queue (instead of PCB, w/ TCB)
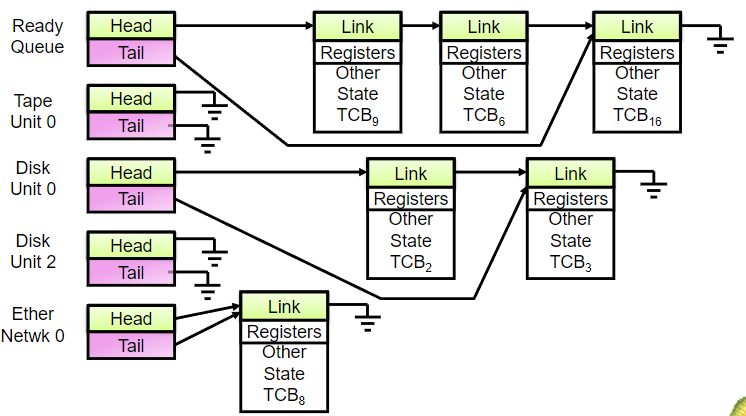
- thread not running: TCB is in some queue
-
User threads and kernel threads
- user threads: independently executable entity within a program
- created & managed by user-level threads library
- users: only visible to programmers
- kernel threads: can be scheduled & executed on a CPU
- supported & managed by OS
- users: only visible to OS
- example: virtually all-general purpose OS
- Windows, Linux, Max OS X iOS, Android
- user threads: independently executable entity within a program
-
Multithreading models
- as user threads: invisible to kernel
- => cannot be scheduled to run on a CPU
- OS: only manages & schedules kernel threads
- thread libraries: provide API for creating & managing user threads
- primary libraries
- POSIX Pthreads - POSIX API
- Windows threads - Win32 API
- Java threads - Java API
- primary libraries
- user-level thread: providing concurrent & modular entities
- in a program that OS can take advantage of
- 👨🎓 here! this can be done in parallel manner!
- if no user threads defined: kernel threads can't be scheduled either
- ❓ are kernel threads assigned on runtime?
- 👨🏫 yes; user threads are static though
- cycles of threads / control / etc.: applies to kernel threads
- in a program that OS can take advantage of
- example
pthread_t tid; /* creating thread */ pthread_create(&tid, 0, worker, NULL) - ultimately: mapping must exist for user-kernel threads
- common ways:
- many-to-one: many user-level thread to one kernel thread
- one-to-one: one user-level thread for a kernel thread
- most common in modern OS
- many-to-many: many user-level thread to many (usually smaller no. of) kernel thread
- as user threads: invisible to kernel
COMP 3511: Lecture 10
Date: 2024-10-08 14:53:43
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Threads (cont.)
-
Multithreading models (cont.)
-
Multithreading: many-to-one
- many user thread: mapped to single kernel thread
- only one user thread mapped to kernel thread at execution time
- which user thread is mapped: scheduling problem
- one thread blocking (of thread): causes
- cases all
- m
- no performance benefit
- still, structure-wise works like multithreading
- cannot run in parallel on multicore system
- as one kernel thread: can be active at a time
- examples
- Solaris Green Threads
- GNU Portable Threads
- 👨🏫 used in the past due to resource limitation
- kernel thread: requires resource
- user thread: piece of code waiting for execution
- few systems currently use this model
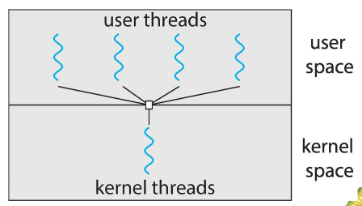
-
Multithreading: one-to-one
- each user-level thread: maps to one kernel threads
- maximum concurrency: allows multiple threads to run in parallel
- having more kernel threads than user threads: meaningless
- i.e. creation of user thread: mandates kernel thread creation
- max no. of threads / process: might be restricted due to overhead
- could have been problematic in the past
- as kernel thread consumes resources: memory, IO, etc.
- examples
- Windows
- Linux
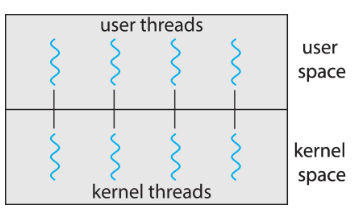
-
Multithreading: many-to-many
- multiplexing many user=level
- in-between
- process-contention scope: to be discussed later (Ch. 5)
- 👨🏫 similar to many-to-one mapping
- we have scheduling problem
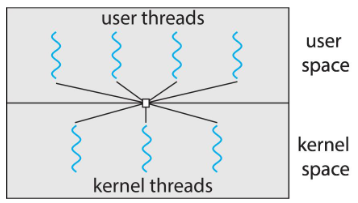
-
Multithreading: two-level
- similar to many-to-many
- but: it allows user thread to be bound to kernel thread
- e.g. some user thread: significant, and requires set kernel thread
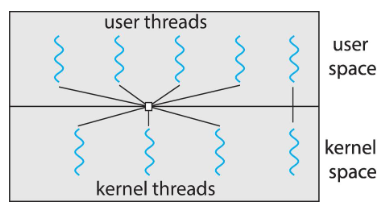
-
Multithreading mapping models
- many-to-many: most flexible
- but difficult ti implement in practice
- in modern computer: limiting no. of kernel threads: less of a problem
- thanks to multi core
Threading Issues
-
fork(),exec()semantics- does
fork()by thread: duplicate only the calling thread?- or all threads of a process?
- some UNIX versions: chosen two versions of
fork()- if
exec()called immediately after forking: duplicate only calling thread exec(): works as normal - replacing the entire process (although only calling thread is copied)- 👨🏫 'one' of the improvement case
- if
- different improvements exist!
- does
-
Signal handling
- signals: notify a process that a particular event has occurred
- can be receives synchronously / asynchronously
- based on source / reason
- synchronous signals: delivered to same process performing operation causing signal
- d.g. illegal memory access / division by 0
- signals: handled in different ways
- some signals: ignored
- some: handled by terminating program
- e.g. illegal memory access
- signal handler: process signal
- signal: generated by a particular event
- delivered to a process
- handled by one of two signal handlers
- default vs. user defined
- every signal: w/ default handler that kernel users
- where signal shall be delivered for a multi-thread process?
- deliver: signal to thread to signal applies
- deliver: signal to every thread in process
- deliver: signal to certain thread in process
- assign a specific thread to receive all signals
- method of delivering signal: depends on signal type
- synchronous signal: delivered to thread causing the signal (not other threads)
- asynchronous signals (e.g. termination process): sent to all threads
- UNIX function for delivering
killsignal: send to all thread of the process- s
- specifies
pid
- POSIX Pthread function: allows signal to be delivered to a specified thread
- specifies
tid
- specifies
- d
- signals: notify a process that a particular event has occurred
-
Thread cancellation
-
terminating thread before finishing
- thread to be cancelled: target thread
-
cancellation scenario
- asynchronous cancellation: terminate target thread immediately
- deferred cancellation: target thread: periodically check if it should terminate
- allows termination in orderly fashion
- e.g. when modifying an inter-process variable / in critical point, target thread shouldn't be terminated
-
invoking thread cancellation: requests cancellation
- actual cancellation: depending on thread state / type
-
w/ Pthreads:
-
by nature: cancellation of a thread affects other threads within the same process
mode state type off disabled deferred enabled deferred asynchronous enabled asynchronous Pthread code for created cancel of a thread
#include <pthread.h> #pthread_t tid /* create the thread */ pthread_create(&tid, 0, worker, NULL); // worker: a start routine / function call /* cancel the thread */ pthread_cancel(tid); /* wait for the thread to terminate */ pthread_join(tid, NULL);
-
-
OS example: Windows
- Windows application: runs as a separate process
- Windows API: primary API for Windows app
- w/ one-to-one mapping
- general components of a Window thread
- tid
- register set
- PC
- separate user / kernel stacks
- context of a thread: register set, stacks, and private storage areas
- primary data structures of a thread
- ethread
- kthread
- TEB (thread environment block)
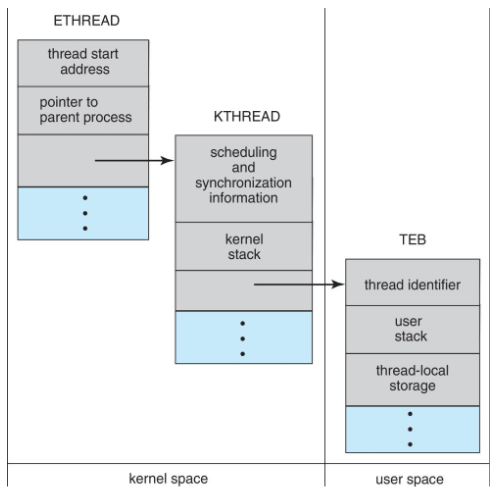
-
OS example: Linux
- Linux: does not differentiate threads & process
- special kind of process: task
- thread in Linux: process that (may) share certain resource w/ other thread
- each thread: w/ unique
task_structand appears as a normal process - threads in Linux: happens to share everything (except context)
- e.g. address space
- then they behave like threads
- ⭐👨🏫 Linux approach: provides much flexibility
- e.g. sharing program, but not data
- or sharing data, but program
- or sharing file, but nothing else
- impossible with traditional approach
- each thread: w/ unique
- contracts greatly w/ Windows / Sun Solaris
- w/ explicit kernel support for threads / lightweight processes
- if a process: consist of two threads
- in Windows
- in Linux: simply 2 tasks w/ normal
task_structstructure- that are set up to share resources
- threads: created just like normal tasks
- except:
clone()syscall used to pass flag clone(): allows a child task to share part of execution context w/ parentclone(): specifies what to share- 👨🏫 fork / clone: creates a new task
clone(): only in Linux
- flags control behavior
- except:
- instead of copying all data structures
- new task points to data structures of parent task
- normal
fork(): can be implemented asclone(SIGCHLD, 0);
- Linux: does not differentiate threads & process
CPU Scheduling: Basic Concepts
-
Basic concepts
- objective of multiprogramming: have process running at all time
- i.e. maximize CPU utilization
- process execution: made of cycles of CPU execution & IO wait
- ask CPU burst and IO burst
- 👨🏫 based on what you are doing at the point
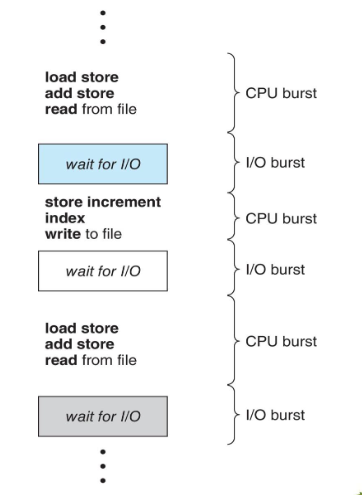
- when CPU idle:
- OS try to select one process on ready queue & execute
- unless ready queue is empty = no process in ready state
- selection of process: done by CPU scheduler
- aka process scheduler, short-term scheduler
- objective of multiprogramming: have process running at all time
-
History of CPU-burst times
- majority of CPU burst time: very short
- but very few CPU extensive jobs exist
- aka: long-tail distribution
- typically
- d
- distribution: matters when we design a CPU-scheduling algorithm
- majority of CPU burst time: very short
-
CPU scheduler
- CPU scheduler: selects on process thread on ready queue
- i.e. what to be executed next?
- queue
- CPU scheduling: may take place in following 4 conditions (when scheduling must be done)
- switching from running -> waiting state (e.g. IO request / wait)
- process terminates
- giving up CPU voluntarily
- switching from running to ready state
- i.e. interrupt
- switching from waiting to ready / new to ready
- e.g. completion of IO
- new process arrives on ready queue w/ higher priority
- if it is priority-based scheduling
- case 1 & 2: non-preemptive
- giving up CPU voluntarily
- case 3 & 4: preemptive
- OS: forces to give up CPU
- consider access to: shared data
- CPU scheduler: selects on process thread on ready queue
-
Dispatcher
- dispatcher module: allocates CPU to process selected by scheduler
- involves:
- no. of context switches:
- can be obtained by
vmstaton Linux - ~= hundred context switches / sec usually
- can be obtained by
-
Scheduling criteria
- CPU utilization: fraction of the time that CPU is busy
- as long as ready queue is not empty: CPU must not be idle
- 👨🏫 priority no matter what scheduler you use
- throughput: no. of process / job completed per time
- response time: only matters for robin-round
- fairness
- computation of each: will be explained later
- generally: desirable to optimize all criteria
- but there might be conflict, which different considerations in practice
- mostly
- in practice: we prefer to optimize minimum / maximum values rather than average
- and there are many things to be considered
- 👨🏫 interactive
- interactive: CPU
- non-interactive: does not require sCU attention until termination
- e.g. ML communication
- CPU utilization: fraction of the time that CPU is busy
COMP 3511: Lecture 11
Date: 2024-10-10 14:55:18
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
CPU Scheduling Algorithms
- 👨🏫 assume: all under single processor system
-
First-Come First-Served: FCFS
- if arrives in respective order
- waiting time: each process in "ready stage"
- time joining CPU burst - arrival time
- ⭐⭐ = turn-around time - CPU burst time
- turn-around time: total time to execute a particular process
- ⭐⭐ = completion time - arrival time
- (for single process system)
- 👨🏫 waiting & turn around time: must be computed manually
- earlier system: FCFS = one program is scheduled to run until completion
- in multiprogramming systems: process finishes its current CPU time
- example

- waiting time:
- avg.waiting time:
- avg. turn-around time:
- or:
- example 2

- waiting time:
- avg.waiting time:
- avg. turn-around time:
- Convoy effect: short process: stuck behind a long process
- bad for short jobs, depending purely on arrival order
- e.g. one CPU -bund & many IO-bound processes
- FCFS: result in low IO device utilization
- problem: you can't know execution time of the program beforehand!
-
Round Robin (RR)
- straightforward solution
- if process takes longer than expectation (e.g. found from the curve)
- FCFS: non-preemptive
- once CPU core allocated process, process keeps it until release
- RR: preemptive
- each process w/ small unit of CPU time (time quantum )
- 10-100 ms
- after time elapse: process is preempted and added to the end of ready queue
- each process w/ small unit of CPU time (time quantum )
- given long process, each process: gets portion of CPU time
- per each round
- (ignoring context switching)
- waiting time: always less than time units
- timer: interrupt every quantum to schedule next process / process blocks
- upon completing current CPU burst time
- when its CPU burst time / remaining CPU time
- i.e. quicker than expectation?
- example: w/

- waiting time:
- avg. waiting time:
- avg. turn-around time:
- response time:
- average: 7
- i.e. first response time - request time
- 👨🏫 same as turn-around for FCFS/FIFO
- remaining CPU burst time
- average waiting time: can be long
- but inherently "fairer" than FCFS
- offers better average response time: important for interactive jobs
- straightforward solution
-
Time quantum and context switch time
- performance of RR: depends heavily on choice
- large : FCFS
- small : interleaved, but high overhead from context switch time
- context switch time: micro sec
- performance of RR: depends heavily on choice
-
FCFS - RR comparison
-
is RR: always better than FCFS?
-
extreme example: quantum = 1
- and 10 jobs starting same time, with 100 CPU burst time
Job # FIFO RR 1 100 991 2 200 992 9 900 999 10 1000 1000 -
average job turn-around time: much worse
- albeit with two extreme conditions
- very small quantum size
- all jobs with same length
- yet: average response time: much better
- albeit with two extreme conditions
-
example
process time 6 3 1 6 -
turnaround time: varies with time quantum
- average turnaround time: not necessarily improve when quantum increases
- it can be, generally, when most processes finish current CPU bursts within a single quantum
- yet: large quantum leads to FCFS
-
⭐ rule of thumb: 80% of CPU bursts: should be shorter than the time quantum
- quantum: should be enough to produce meaningful result for most cases
-
👨🏫 can be adjusted on the way
- actually... we have better algorithms than pure RR
-
-
Short-Job-First (SJF)
- what if: we know next CPU burst time of each process?
- then, we can process the shorted job first
- for given set of processes, this is optimal (i.e. min avg. waiting time)
- difficulty: knowing length of next CPU request
- big effect on short jobs, rather than long ones
- more precise name: shortest-next-CPU-burst
- can be applied to entire program / current CPU burst only
- response time: not concerned now
- 👨🏫 as this is introduction of concepts
- example
process time 6 8 7 3 
- average waiting time:
- best FCFS = case of SJF
- actually,
-
Determining length of next CPU burst
-
estimation: done by exponential average (again :p)
- : average length of -th burst
- : predicted value for next CPU burst
-
- larger : weight / portion of the most recent data
- define:
-
commonly:
-
preemptive version: called shorted-remaining-time-first (SRTF)
diagram
-
examples of EMA
- :
- first estimation lasts forever
- :
- only last CPU burst counts
- current prediction: dependent on all of past data
- yet, the effect of past exponentially reduces
- :
-
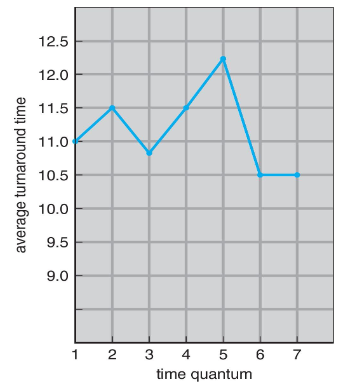
COMP 3511: Lecture 12
Date: 2024-10-15 14:35:33
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
CPU Scheduling Algorithms (cont.)
gantt
A task :a1, 1, 30s
Another task :a2, after a1, 20s
Another task :a3, after a2, 20s
Another task :a4, after a3, 20s
axisFormat %S
-
SJF: can either be preemptive / non=preemptive
-
what if: new process arrives while another is executing?
- CPU: might switch to new process (if w/ shorter remaining time)
-
SRJF: SJF, but preemptive
-
example
process arrival burst 0 8 1 4 2 9 3 5 
- average waiting time:
-
SJF/SRTF and FCFS comparison
- possible: results in starving
- process w/ long burst time might keep delayed
- - possible: results in starving
-
Priority scheduling
- priority no.: associated w each process
- CPU: allocated to process w/ highest priority (= smallest integer)
- preemptive
- non-preemptive
- equal-priority process: scheduled in FCFS
- SJF: special case of priority scheduling algorithm
- priority: inverse of predicted next CPU burst
- problem: starvation: low priority process never executing
- solution: aging: as time progresses, priority process
- other solutions exist
- 👨🏫 or: periodically update the priority
- example
process burst priority 10 3 1 1 2 4 1 5 5 2 
- average waiting time: 8.2 msec
- when 2 ms quantum applied, w/ RR:
- 👨🏫 combination between priority and RR!

-
Multilevel queue
- multilevel queue scheduling: can be extension of priority scheduling
- e.g. priority assigned statically
- process: remains in the same queue for duration of runtime
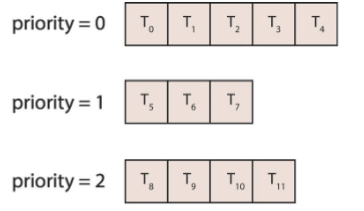
- partition processes: depending on process type
- scheduling among queues: commonly implemented w/ fixed priority preemptive scheduling
- each queue w/ certain CPU time / time-slice
- scheduling among queues: commonly implemented w/ fixed priority preemptive scheduling
- multilevel queue scheduling: can be extension of priority scheduling
-
Multilevel feedback queue (MLFQ)
- process: move between various guess
- aging: implemented this way
- supports flexibility
- following parameters
- no. of queues
- scheduling algorithms for each queue
- method to determine when to upgrade / demote a process
- method to determining which queue to enqueue process
- example
- three queues
- : RR w/ ms
- : RR w/ ms
- : FCFS
- scheduling
- new job entering : served FCFS
- preempts jobs from if they are running
- if it doesn't finish in 8 ms: enqueue process to
- : served FCFS and receives 16 ms
- if it doesn't complete: enqueue process to
- if: a job from : preemptive by a new job of higher queue
- remains at the front of that queue (w/ remaining quantum)
- new job entering : served FCFS
- approximates SRTF
- CPU bound jobs: drop quickly
- short-running IO bound: stays near top
- 👨🏫 running on a CPU: means that queues above are empty
- upon preemption: interrupted process still stays front of the queue
- when prioritized process ends: (i.e. priority returns to second queue)
- then the interrupted process continues its remaining time quantum
- three queues
- process: move between various guess
-
Computation
- turnaround time: termination time - arrival time
- waiting time: turnaround time - CPU burst time
---
displayMode: compact
---
gantt
axisFormat %S
Requirements :a1, 1, 4s
Design :a2, after a1, 4s
Development :a3, after a2, 4s
Test :a4, after a3, 4s
-
MLFQ: Remarks
- MLFQ: commonly used in many systems (unix, Solaris, Windows, etc.)
- w/ distinctive advantages
- no need for prediction of CPU burst time
- handles interactive jobs well
- better than RR in terms of response time
- i.e. first quantum
- produces similar performance w/ SJF / SRTF
- short jobs: finish at Q0
- SJF / SRTF: theoretical & optimal
- MLFQ: practical & approximates
- fair: on performance for CPU-bound jobs
- no "complete" starvation
- possible starvation: handled by reshuffling jobs to different queues
- e.g. after some period: move all jobs to top queue
- 👨🎓 shake!
- 👨🏫 wonderful (& best) principle!
- no, or very little overhead!
- ❓ is there any criteria for quantum 1, 2, etc. in MLFQ?
- first quantum: 7-80%
- second: somewhat of a buffering - until it goes to FCFS
- design: must be considered carefully
- 2 level: may be better than 3-4
- CPU intensive environment, e.g. ML, has different consideration w/ DB query handler
Other Scheduling
-
Thread scheduling
- user thread: handled by programs
- no scheduler needed for on-to-one mapping
- yet: many-to-one or many-to-(smaller) many: requires scheduling on thread
- i.e. which task is mapped to thread currently?
- OS: uses intermediate data structure: lightweight process (LWP)
- between user threads & kernel threads
- programmer: assigns thread priority in program
-
Multiple-processor scheduling
- asymmetric: not to be discussed
- i.e. when one processor acts as a master
- symmetric multiprocessing (SMP)
- each processor: either self-scheduling or w/ one common ready queue
- e.g. one line for all counter (airport) / each counter (supermarket)
- both are common for SMP
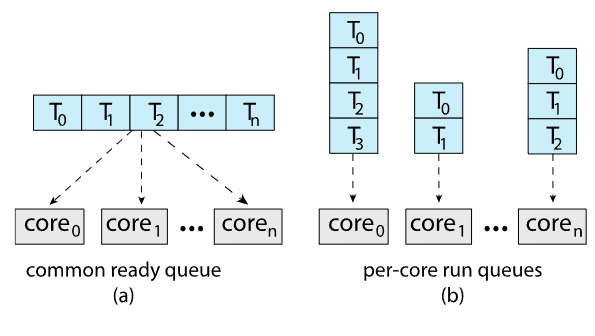
- each processor: either self-scheduling or w/ one common ready queue
- asymmetric: not to be discussed
COMP 3511: Lecture 13
Date: 2024-10-17 15:00:44
Reviewed:
Topic / Chapter:
summary
❓Questions
- ❓ if one process happens to miss deadline once in a cycle, will it miss deadline again in the next cycle?
- 👨🏫 maybe, maybe not! depends on arrival, deadline, etc.
- ❓ what if: we know in prior that a process will miss deadline?
- depends on whether the deadline is soft or hard
- also, different mechanism handles it differently
- for hard deadline, you may ignore the step in some cases
- if the workload is >100% (impossible), it's not scheduler's problem!
Notes
Other Scheduling (cont.)
-
Multicore processor
- recent trend: multiple processor cores on same physical chip
- faster & consumes less power
- but: complicate scheduling design
- memory stall: waits long time waiting for memory / cache to respond
- as processors are much faster than memory
- 👨🏫 inherent problem of Von-Neumann architecture
- solution: having multiple hardware threads per core
- each hardware thread: w/ own state, PC, register set
- appearing as a logical CPU: running a software thread
- chip multithreading (CMT)
- 👨🏫 dealing with two program, without idle state!
- ideal case
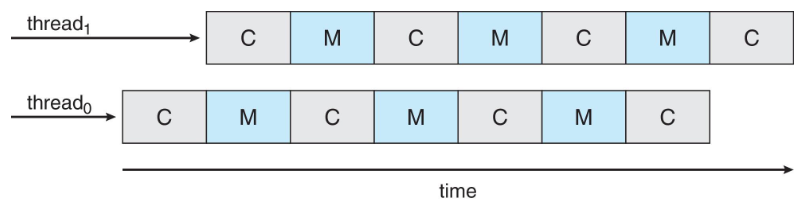
- 👨🏫 in reality: memory operation might be much longer than CPU operation
- then, we can have more hardware threads than just 2
- each hardware thread: w/ own state, PC, register set
- scheduling: can take advantage of memory stall
- to make progress on another hardware thread, while another doing memory task
- core: switching to another thread - dual-thread processor core
- 👨🏫 there is no software overhead, as it's hardware
- thus, it's very fast
- dual-threaded, dual-core system: presents 4 logical processors to OS!
- e.g. UltraSPARC T3 CPU: w/ 16 cores / chip and 8 hardware threads per core
- appearing to be 128 logical processors
- e.g. UltraSPARC T3 CPU: w/ 16 cores / chip and 8 hardware threads per core
- recent trend: multiple processor cores on same physical chip
-
Multithreaded multicore system
- from OS view: each hardware thread maintains its architecture state
- thus: appears as a logical CPU
- CMT: assigns each core multiple hardware threads
- Intel term: hyperthreading
- 👨🏫 logical != physical
- you can't simultaneously run all those jobs
- two levels of scheduling exist
- OS: decide which SW thread to run on a logical CPU (in CPU scheduling)
- each core: decide which hardware to run on physical core
- possible: RR scheduling
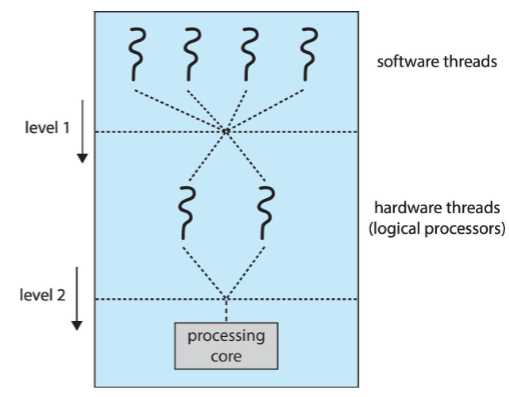
- from OS view: each hardware thread maintains its architecture state
-
Multithreaded multicore scheduling
- user-level thread: schedule to LWP / kernel-level thread
- for many-to-one or many-to-many: thread library schedules user-level threads
- such threads: process contention scope (PCS)
- typically: based on priority (set by programmers)
- for many-to-one or many-to-many: thread library schedules user-level threads
- software thread (=kernel thread): scheduled on logical CPU = hardware thread
- 👨🏫 OS is responsible for this only
- hardware thread: scheduled to run on a CPU core
- each CPU core: decides scheduling, often using RR
- user-level thread: schedule to LWP / kernel-level thread
Processor Allocation
-
Processor affinity
- process: has affinity for a processor on which it runs
- cache contents of processor: stores on memory accesses by that thread
- called as processor affinity
- cache contents of processor: stores on memory accesses by that thread
- high cost of invalidating in repopulating caches
- most SMP: try to avoid migration!
- essentially: per-processor ready queues: provide processor affinity for free
- soft affinity: OS: attempts to keep process running on same processor (no guarantee)
- possible for process to migrate: during load balancing
- hard affinity: allow a process to specify: subset of processors it may run
- 👨🎓 I want this, that, and this only!
- many systems: provide both soft & hard affinity
- e.g. Linux implements soft affinity, yet also provides syscall
sched_setaffinity()for hard affinity
- e.g. Linux implements soft affinity, yet also provides syscall
- process: has affinity for a processor on which it runs
-
Load balancing
- 👨🏫 only focusing on load balancing: common queue for all cores are good
- same for separate queue and affinity
- everything comes at a cost!
- load balancing: attempts to keep workload evenly distributed
- two general approaches to load balancing
- push migration: specific task: periodically check load on each processor
- if imbalance found: pushes overloaded CPU's task to less-busy CPUs
- pull migration: idle processors: pull waiting tasks from a busy processor
- not mutually exclusive: can be both implemented in parallel on load-balancers
- e.g. Linux CFS implements both
- push migration: specific task: periodically check load on each processor
- load balancing: often counteracts benefits of processor affinity
- natural tension between load balancing & minimizing memory access times
- scheduling algorithms for modern multicore NUMA systems: quite complex
- 👨🏫 only focusing on load balancing: common queue for all cores are good
-
Real-time CPU scheduling
- demands: performance guarantee - predictability
- especially in embedded control, etc.
- e.g. spaceship must respond within certain time
- hard real-time systems: with stricter requirements
- task: must be serviced by deadline
- service after deadline: expired, and meaningless
- soft real-time systems
- provides: no guarantee to when critical real-time process will be scheduled
- guarantee tha real-time process: given preference over noncritical process
- 👨🏫 we will be discussing this now!
- must support: priority-based algorithm w/ preemption
-
Priority-based scheduling
- processes: w/ periodic characteristic: requires CPU at constant intervals (periods)
- has: processing time , deadline , period :
- 👨🏫 if : CPU must always be working on this
- rate of periodic task:
- has: processing time , deadline , period :
- process: must announce its deadline requirements
- scheduler: decides whether to admit process or not
- processes: w/ periodic characteristic: requires CPU at constant intervals (periods)
-
Rate monotonic scheduling
- static priority: assigned based on inverse of period
- shorter period: higher priority
- rationale: assign priority to frequent (CPU) visitor
- suppose:
- w/ period=deadline 50, processing time 20
- w/ period=deadline 100, processing time 35
- as : w/ higher priority than
- : occupied time
- : occupied time
- 👨🏫 75% utility if both can be scheduled!
- if the sum is more than 100%: can't be scheduled at all
- schedule example
- 👨🏫 is tricky - it's preemptive!
- missing deadline
- w/ period=deadline 50, processing time 25
- w/ period=deadline 70, processing time 35
- as : w/ higher priority than
- : occupied time
- : occupied time
- 👨🏫 94% utility if both can be scheduled!
- P2: missing deadline by finishing at time 85

- static priority: assigned based on inverse of period
-
Earliest deadline first scheduling (EDF)
- Earliest deadline first: assigns priorities dynamically according to deadline
- earlier the deadline: higher the priority
- e.g. w/ same case as above:

- 👨🏫 "first" has higher priority than "first"
- but second has lower priority than first
- no preemption of first by second !
- notably: first () preempts second ()
- 👨🏫 logically equivalent to SRTF
- Earliest deadline first: assigns priorities dynamically according to deadline
-
Rate-monotonic vs. EDF scheduling
- rate-monotonic: schedules periodic tasks w/ static priority w/ preemption
- considered optimal among static priority-based algorithm
- EDF: does not require process to be periodic, nor constant CPU burst time
- only requirement: process announce deadline when it becomes runnable
- EDF: theoretically optimal
- schedule processes s.t. each process: meet deadline requirements
- and CPU utilization will be 100 percent
- in practice: impossible to achieve such level
- as: cost of context switching & interrupt handling, etc.
- optimal: cannot find a better scheduler w/ smaller number of deadline misses
- rate-monotonic: schedules periodic tasks w/ static priority w/ preemption

Algorithm Evaluation
-
Algorithm evaluation
- selecting CPU scheduling algorithm: might be difficult
- different algorithms: w/ own set of parameters
- selecting CPU scheduling algorithm: might be difficult
-
Deterministic modeling
- takes: particular predetermined workload
- and define: performance of each algorithm for that workload
-
Queueing analysis
- through actual numbers (arrival time, CPU bursts, etc.)
- 👨🏫 there can be 2 PG courses on this!
- Queueing models
- mathematical approach for stochastic workload handling
- : average queue length
- : average queue length
- : average arrival rate into queue
- usually given
- Little's formula:
- 👨🏫 my PhD thesis owa on this :p
- more details: Poisson and Markov chain...
- 👨🏫
- : CPU burst time
- unless: overload :p
-
Simulations
- queueing models: not "very" practical, but interesting mathematical models
- restricted to few known distributions
- more accurate: simulations involving program of a computer system model:
- queueing models: not "very" practical, but interesting mathematical models
-
Simulation implementation
- even simulations: w/ limited accuracy
- build a system: allowing actual algorithms to run w/ real data set
- more flexible & general
- 👨🏫: no true optimal solution exists
COMP 3511: Lecture 14
Date: 2024-10-22 15:07:19
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Synchronization Tools
-
Background
- processes: execute concurrently
- might be interrupted at any time, for many possible reasons
- concurrent access to any shared data: may result in data inconsistency
- maintaining data consistency: requires OS mechanism
- to ensure orderly execution of cooperating processes
- processes: execute concurrently
-
Illustration of Problem
- e.g. producer-consumer problem
- integer
counter: used to keep track of no. of buffers occupiedcounter = 0initially- incremented each time producer places item in buffer
- decremented each time consumer consumes item in buffer
- example code
// producer while (true) { // produce an item while (counter == BUFFER_SIZE) ; buffer[in] = next_produced; in = (in + 1) % BUFFER_SIZE; counter++; } while (true) { while (counter == 0) ; // do nothing next_consumer = buffer[out]; out = (out + 1) % BUFFER_SIZE; counter--; // consume an item } - race condition:
counter++can be made as:register1 = counter register1 = register1 + 1 counter = register1counter--can be made as:register2 = counter register2 = register2 - 1 counter = register2- order of execution: cannot be determined
- following scenario is possible, from
counter = 5
register1 = counter // 5 register1 = register1 + 1 // 6 register2 = counter // 5 counter = register1 // counter = 6 register2 = register2 - 1 // 4 counter = register2 // counter = 4 - following scenario is possible, from
- expected result:
counter = 5- but trouble happened!
- only internal order of consumer / producer can be trusted, but not inter-process
- 👨🏫 fundamental problem of sharing data
- very hard to debug, and happens in small chance
- individual code & logic: has no error!
- similar case:
fork()occurring at almost same time- resulting in: identical
pid
- resulting in: identical
- must be: no interleave with another process sharing the variable
-
Race condition
- race condition: undesirable situation where several processes access / manipulate shared data concurrently
- and outcome of executions: depend on particular order access / executions take place
- which is not guaranteed
- thus: resulting in non-deterministic result
- and outcome of executions: depend on particular order access / executions take place
- critical section segment: during which
- process / thread: changing shared var., updating a table, writing a file, etc.
- must ensure: when one process is in critical section, no other can be in its critical section
- mutual exclusion and critical section: implies the same
- 👨🏫 can be long, can be short (= hundreds of lines)
- critical section problem: to design a protocol to solve it
- i.e. each process:
- ask permission before entering a critical section (entry section)
- notify exit (exit section)
- and remainder section
- i.e. each process:
- general structure
do { // entry section critical section // do something critical // exit section remainder section // others can access critical section } while (true);
- race condition: undesirable situation where several processes access / manipulate shared data concurrently
-
Solution of critical section problem
- 3 solutions
- mutual exclusion: if process is in its critical section
- no other processes can be executing their critical section
- progress: if a process wish to inter critical sections, it cannot de delayed / waited for indefinitely
- i.e. must know no. of process in front of queue, etc. must be in
- bounded waiting: bound: must exist on no. of time processes are allowed to enter
- 👨🎓 one shouldn't use toilet alone for too long
- assume: each process execute at nonzero speed
- and with no assumption on relative speed on individual process
- mutual exclusion: if process is in its critical section
- critical section problem in kernel
- kernel code: code OS is running
- subject to: many possible race conditions
- kernel data structure: keeps list of all open files
- that can be updated by multiple kernel processes
- other kernel DS: e.g. for maintaining memory allocation, process lists, interrupt handling, etc.
- two general approaches
- preemptive: let preemption of process running in kernel mode
- possible race condition
- more difficult to maintain in SMP architecture
- 👨🏫 much more effective!
- possible race condition
- non-preemptive: runs until exiting kernel mode, blocks, or giving up CPU
- free of race conditions in kernel mode
- only possible in single-processor system
- preemptive: let preemption of process running in kernel mode
- kernel code: code OS is running
- 3 solutions
-
Synchronization tools
- many systems: provide hardware support on critical section code implementation
- for uni-processor systems: simply disable interrupts
- such approach: inefficient for multiprocessor
- OS: provide hardware & high level API support for critical section code
- example
programs share programs hardware load / store, disable interrupts, test & set, compare & swap high level APIs locks, semaphores - synchronization hardware
- modern OS: provides atomic hardware instructions
- atomic: non-interruptible
- ensures: execution of atomic instruction: cannot be interrupted
- => no race condition!
- building blocks for more sophisticated mechanisms
- two commonly used atomic hardware instructions
- test a memory word & set a value:
Test_and_Set() - swap contents of two memory words:
Compare_and_Swap()
- modern OS: provides atomic hardware instructions
- implementation
Test_and_Set()bool test_and_set(bool *target) { bool rv = *target; *target = true; // set here return rv; }- if
targetwas initiallytrue: than it returnstrue- i.e. we shouldn't interfere
- integrated solution: let shared boolean var.
lock, initiallyfalsedo { while (test_and_set(&lock)) ; critical section // do something critical lock = false; remainder section // others can access critical section } while (true)- 👨🏫 this: only guarantees mutual exclusion!
- dedicated data structure exist for those test variables
- if
Compare_and_Swap()bool compare_and_swap(int *value, int expected, int new_value) { int temp = *value; if (*value == expected) *value = new_value; return temp; }- 👨🏫 return value: doesn't change
- it only determines: whether I edit the variable or not
- example
do { while (compare_and_swap(&lock, 0, 1) != 0) ; critical section // !!! lock = 0; remainder section // !!! } while (true);- ❓ can we modify it a bit and
- this function code can be used,
- but use of more sophisticated tools built upon primitives: easier
- ❓ can we modify it a bit and
- direct use of primitive: for bounded-waiting mutual exclusion
do { waiting[i] = true; key = true; // local variable while (waiting[i] && key) key = test_and_set(&lock); waiting[i] = false; critical section // !!! j = (i + 1) % n; while ((j != i) && !waiting[j]) j = (j + 1) % n; if (j == i) lock = false; // no one waiting: release the lock else waiting[j] = false; // unblock process j // force process j to get out of waiting loop remainder section // !!! } while (true); - shared:
lock&waiting; local:key
- 👨🏫 return value: doesn't change
- sketch proof
- mutual exclusion: : enters critical section only if:
- either
waiting[i]=falseorkey=falsekey=falseonly iftest_and_setis executed- only first process executing
test_and_setfindkey==false- others: wait
waiting[i]: can become false only if another process leaves critical section- only one
waiting[i]set to false
- only one
- maintain: mutex requirement
- either
- progress: process exiting its section:
- either set
locktofalseorwaiting[j]tofalse - both: allow a waiting process to enter the critical section to proceed
- either set
- bounded waiting: count in turns
- when a process leaving critical section:
- it scans array waiting in cyclic order
{i+1, i+2, ..., n-1, 0, 1, ..., i-1}
- then designates: first process in the ordering w/
waiting[j]- as next one to enter critical section
- it scans array waiting in cyclic order
- 👨🏫 worst case: waiting
n-1processes in front of me
- when a process leaving critical section:
- mutual exclusion: : enters critical section only if:
- many systems: provide hardware support on critical section code implementation
-
Atomic variables
- provides atomic updates on basic data types (integers & booleans)
- e.g.
increment()on atomic variable ensures increment without interruptionvoid increment(atomic_int *v) { int temp; do { temp = *v; } while (temp != (compare_and_swap(v, temp, temp+1)) ); }- supported by Linux
-
Mutex locks
- OS: builds a no. of SW tools to solve critical section problem
- supported by most OS: mutex lock
- to access a critical region: must ask
acquire- use
release()after use
- use
- calls to
acquire(),release()- must be atomic- often implemented via hardware atomic instructions
- however: solution requires busy waiting - must keep checking
- thus: has a nickname: spinlock
- wastes CPU cycles due to busy waiting
- advantage: context switch is not required when process is waiting
- context switch: might take long time
- spinlock: thus useful when locks: expected to hold short
- often used in multiprocessor systems
- as one thread: spin on one processor
- while another thread performs its critical section on another processor
- as one thread: spin on one processor
- advantage: context switch is not required when process is waiting
acquire()andrelease()- solution: based on the idea of lock on protecting critical section
- operations: atomic
- lock before entering critical section (accessing shared data)
- unlock upon departure from critical section after access
- wait if locked: synchronization = involves busy waiting
- "sleep" or "block" if waiting for a long time
void acquire() { while (!available) ; /* busy wait */ available = false; } void release() { available = true; } do { acquire lock // critical section release lock // remainder section } while (true);- solution: based on the idea of lock on protecting critical section
COMP 3511: Lecture 15
Date: 2024-10-24 15:15:04
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Synchronization Tools
-
Semaphore
- semaphore : non-negative integer variable
- a generalized lock
- first defined by Dijkstra in late 1960s
- can behave similarly to mutex lock, but has more sophisticated usage
- min synchronization primitive used in original UNIX
- two standard operations for modifying:
wait()andsignal()- originally
P()andV()for proberen (test) and verhogen (increment) in Dutch
- originally
- must be execute atomically s.t. no more than one process: execute
wait()andsignal()on same semaphore at the same time- idea: serialization
- semaphore: only accessible by those two operations, except initialization
void wait(S) { while (S <= 0) ; // busy wait S--; } void signal (S) { S++; }
- semaphore : non-negative integer variable
-
Semaphore usage
- counting semaphore: integer value over unrestricted domain
- can be used: for controlling access to given set of resources
- of finite number of instances
- initialized to: no. of resources available
- binary semaphore: integer value, 0 or 1
- can be hav like mutex locks
- 👨🏫 but also can be used in different ways
- can also: solve various synchronization problems
- consider : sharing a common semaphore
synch- initialized to 0- following code: ensures that process executes before execute
P_1: S_1; signal(synch); P_2: wait(synch); S_2;
- counting semaphore: integer value over unrestricted domain
-
Implementation with no busy waiting
- each semaphore: associated w/ waiting queue
- each entry in waiting queue: w/ two data ideas
- value (in integer)
- pointer to next record on queue
- two operations
- block: place process invoking operation to (appropriate) waiting queue
- wakeup: remove one of process in waiting queue
- place it on ready queue
- semaphore: may be negative
- w/ classical busy-waiting semaphore: impossible
- if semaphore value = negative:
- magnitude = no. of processes currently waiting on semaphore
-
Signal semaphore
- code
typedef struct{ int value; // if negative: processes being waiting struct process *list; } semaphore; wait(semaphore *S) { S->value--; if (S->value < 0) { add this process to S->list; block(); } } // signal: has chance of changing condition signal(semaphore *S) { S->value++; if (S->value <= 0) { remove a process P from S->list; wakeup(P); } } - notice:
- increment & decrement: done before checking semaphore value
block(): suspends the process & invokes itwakeup(P): resumes execution of a suspended process
- code
-
Deadlock and starvation
- semaphore initialized w/ (binary semaphore)
- forces atomic operation
- deadlock: two / more processes: waiting indefinitely
- for an event: that can be caused oy only one of waiting processes
- e.g. : with half-torn treasure map
- each: request the other part of map
- without giving up the piece they are holding
- won't happen!
- each: request the other part of map
- if : two semaphores initialized to :
wait(S);wait(Q);wait(Q);wait(S);signal(S);signal(Q);signal(Q);signal(S);- : waiting for to execute
signal(Q)- and : waiting for to execute
signal(S) - deadlock!
- and : waiting for to execute
- : waiting for to execute
- starvation: indefinite blocking
- process: may never being removed from semaphore queue
- then: suspended
- e.g. removing process from queue using LIFO
- w/ certain priorities
- process: may never being removed from semaphore queue
- semaphore initialized w/ (binary semaphore)
Synchronization Example
-
Bounded-buffer problem
- counting semaphore for solving a problem!
- buffers, each holding one item
- semaphore
mutexinitialized to1- binary
- semaphore
fullinitialized to0- no. of full slots in buffer
- semaphore
emptyinitialized to- signal(mutex);
- no. of empty slots in buffer
- structure of the producer process
do { // produce item wait(empty); wait(mutex); // guarantee mutual execution // add next produced to buffer signal(mutex); signal(full); // no. of items in buffer } while (true); - structure of the consumer process
do { // remove item from budder to variable wait(full); wait(mutex); // guarantee mutual execution // consume next item from buffer signal(mutex); signal(empty); } while (true);
-
Readers-writers problem
- data set: shared among a no. of concurrent processes
- readers: only read the data, without performing any updates
- writers: can both read & write
- problem: allow multiple readers to read the data set at the same time
- however, at most one writer can access shared data at a time
- several variations on treatment of readers & writers
- w/ different priorities
- simplest solution: requiring no reader be kept waiting
- unless: writer as already gained access to shared data
- shared data update by writers: can be delayed
- as: people are reading (outdated) version
- gives: readers priority in accessing shared data
- shared data update by writers: can be delayed
- unless: writer as already gained access to shared data
- shared data
- data set
- semaphore
rw_mutexinitialized to 1 - semaphore
mutexinitialized to 1 - semaphore
read_countinitialized to 0
- for writer: guarantee mutual exclusion
do { wait(rw_mutex); // writing signal(rw_mutex); } while (true); - for reader: first reader can take over
- prevent another writer from reading it!
do { wait(mutex); // exclusiveness of following snippet read_count++; if (read_count == 1) wait(rw_mutex); signal(mutex); // reading performed wait(mutex); read_count--; if (read_count == 0) signal(rw_mutex); signal(mutex); } while (true); rw_mutex: controls access to shared data for writers & first reader- last reader leaving: release the lock (for potential writer)
mutex: controls the access of readers, to shared variableread_count- writers: wait on
rw_mutex- first reader gain access to critical section: also waiting on
rw_mutex - all subsequent readers: wait on
mutex(held by the first reader)
- first reader gain access to critical section: also waiting on
- data set: shared among a no. of concurrent processes
-
Reader-writer problem variations
- first variation: no reader kept waiting: unless writer gained access
- simple, yet might result in starvation of writers
- thus: potential & significant delay of the object's update
- simple, yet might result in starvation of writers
- second variation: one writer is reader: 'needs' perform update first
- when a writer: waiting for access (either another writer or readers occupying it)
- no new readers: can start reading
- either solution: may result in starvation
- problem: can be solved partially by kernel's reader-writer locks
- multiple processes: permitted to acquire lock in read mode
- yet: only one permitted to acquire lock in write mode
- i.e. specifying: the mode of the lock
- problem: can be solved partially by kernel's reader-writer locks
- first variation: no reader kept waiting: unless writer gained access
Synchronization by OSes
- by: Solaris, Windows XP, Linux, Pthreads
-
Solaris
- implements: variety of locks for support multi-tasking, multi-threading, and multi-processing
- uses: adaptive mutex for efficiency
- when protecting data from short code segments (less than a few hundred instructions)
- starts as: standard semaphore implemented as a spinlock in multiprocessor system
- lock held by a thread running on another CPU: spins to wait for lock
- if held by non-run-state thread: block & sleep waiting
- for signal of lock being released
- condition variables: to be discussed
- wait until condition satisfies
- uses: readers-writers locks when longer sections of code need access to data
- used to protect frequently-accessed data
- used in read-only manner
- relatively expensive to implement
- used to protect frequently-accessed data
-
Windows synchronization
- kernel: using interrupt masks to protect: access to global resources in uni-processor systems
- kernel: uses spinlocks for multi-processor systems
- for efficiency: threads are never preempted when holding a spinlock
- thread synchronization: outside the kernel (user mode)
- Windows: provide dispatcher objects
- threads: synchronize according to several different mechanism
- mutex locks, semaphores, events, timers
- events: similar to condition variables; notify waiting thread when condition occurs
- timers: used to notify one / more thread that specific amount of time has expired
- dispatcher objects: either signaled-state (object available) or non-signaled state (occupied & block / wait)
-
Linux synchronization
-
prior to kernel 2.6: disables interrupts to implement short critical sections
- 2.6 and later: fully preemptive kernel
-
provides:
- semaphores
- spinlocks (for multi-processor)
- atomic integer, and math operations involving it
- reader-writer locks
-
on single CPU: spinlocks replaced by enabling / disabling kernel preemption
-
atomic variables: like
atomic_t- e.g. variable
atomic_t counter; int value;
atomic operation effect atomic_set(&counter, 5);counter = 5atomic_add(10, &counter);counter = counter + 10atomic_sub(4, &counter);counter = counter - 4atomic_inc(&counter);counter = counter + 1value = atomic_read(&counter);value = 12 - e.g. variable
-
-
POSIX synchronization
- POSIX API: provides
- mutex locks
- semaphores
- condition variables
- widely used on UNIX, Linux, an MAcOS
- creating & initializing the lock
#include <pthread.h> pthread_mutex_t mutex; /* create and initialize the mutex lock */ pthread_mutex_init(&mutex, NULL); - acquiring and releasing the lock
/* acquire the mutex lock */ pthread_mutex_lock(&mutex); /* critical section */ /* release the mutex lock */ pthread_mutex_unlock(&mutex); - POSIX condition variables
- associated w/ POSIX mutex lock to provide: mutual exclusion
- 👨🏫 must be in combination
- modification of condition variable itself: not guaranteed to be exclusive
- mutex lock needed
pthread_mutex_t mutex; pthread_cond_t cond_var; pthread_mutex_init(&mutex, NULL); pthread_cond_init(&cond_var, NULL);- waiting for condition
a==bto be true:pthread_mutex_lock(&mutex); while (a != b) pthread_cond_wait(&cond_var, &mutex); pthread_mutex_unlock(&mutex);pthread_cond_wait: in addition to putting the calling thread to sleep- release the lock when putting said caller to sleep
- no other signal: can acquire lock / signal it to wake up
- it also: release on
mutex- thus: others can modify the condition..?
pthread_mutex_lock(&mutex); a = b; pthread_cond_signal(&cond_var); pthread_mutex_unlock(&mutex);- when signalling: make sure to have the lock held
- ensures: there is no race condition
- before returning & being waked up:
pthread_cond_waitre-acquires the lock- ensures: any time: waiting thread is running "between the lock acquired in the beginning"
- lock: release at the end
- 👨🏫 there are situation mutex can replace condition variable
- but there are also situations it can't
- POSIX API: provides
COMP 3511: Lecture 16
Date: 2024-10-29 15:02:18
Reviewed:
Topic / Chapter:
summary
❓Questions
- ❓ if we can analyze deadlock given RAG?
- 👨🏫 yes, given particular RAG: we can identify the deadlock
- then, is it possible to check all possible states of a program
- 👨🏫 theoretically, yet not feasible
- ❓ in EVM / distributed system, how can we apply similar tactics?
- e.g. smart contracts also apply similar idea (e.g. mutex) to prevent reentrancy
- how can we coordinate it across multiple computers? Do we consider each computer as a core?
- 👨🏫 we still consider each computer core as individual cores
- 👨🏫 we can't even work it out for a single computer, how can we do so for entire network?
- overhead will be too much: 10 ~ 20 times slower
- we usually do something similar to deadlock detection
- ❓ Rust utilizes advanced compiler to ensure that there is no memory leak, runtime error, etc.
- can we do similar to programs, so that there won't be issues?
- 👨🏫 too complex, it won't be feasible
- 👨🎓 it would be to compress all as a docker-like gigantic and atomic multi-core process
- can we really call that as a single process at this point?
- ❓ Is deadlock detection somewhat similar to garbage collector?
- in that they check problem regularly
- 👨🏫 yes
Notes
Deadlocks
-
Deadlock in multi-threaded application
- order of threads running: depending on CPU scheduler
- identifying testing deadlocks: hard
- as they may occur only under certain scheduling circumstances
- example code
code - deadlock with lock ordering
void transaction(Account from, Account to, double amount) { mutex lock1, lock2; lock1 = get_lock(from); lock2 = get_lock(to); acquire(lock1); acquire(lock2); withdraw(from, amount); deposit(to, amount); release(lock2); release(lock1); }- transactions: execute concurrently
- 1 transferring 25 from A to B, 2 transferring 50 from B to A
- 👨🏫 we can have deadlock among any no. of processes (not just 2)
- order of threads running: depending on CPU scheduler
-
System model
- system:consist of resources
- resource types:
- : no. of types of resources
- not no. of resources
- e.g. CPU cycles, memory spaces, files, IO devices, semaphores...
- : no. of types of resources
- each resource type : w/ instances
- each process : utilizes a resource as follows
- request
- use
- release
-
Deadlock characterization
- deadlock involving multiple processes: arise if following 4 conditions hold simultaneously
- necessary to not sufficient conditions
- 👨🏫 sufficient condition not known
- mutual exclusion: only ne process at a time: can use a resource
- hold and wait: a process holding a resource, waiting to acquire additional resource (held by anther)
- no preemption: resource: can be released only voluntarily by process holding it
- circular wait: set of waiting process s.t.
- waiting for resource held by
- and for
- if there is dead lock -> conditions hold
- is any of the condition doesn't hold -> no dead lock
- deadlock involving multiple processes: arise if following 4 conditions hold simultaneously
-
Resource-allocation graph
- let graph
- : partitioned into two types
- bipartite!
- : set of all processes in system
- : set of all resource types in system
- request edge: directed edge
- 👨🎓 please give me this resource!
- assignment edge: directed edge
- 👨🎓 this resource belong to xxx!
- example
- 1 instance of
- 2 instances of
- 1 instance of
- 3 instance of
- : holds one and waiting for
- : holds one , one , waiting for
- : holding one
- 👨🏫 no circular wait: no deadlock (for this instance / snapshot)
- example, with deadlock
- cycles exist:
- processes : deadlocked
- graph with a cycle, yet no deadlock
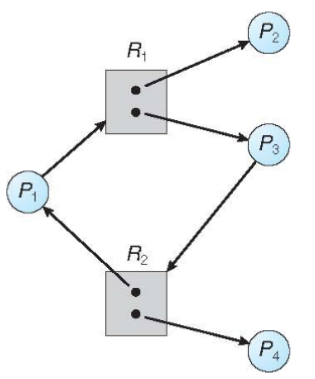
- cycles exist, yet no deadlock
- basic facts
- if a graph has no cycle: no deadlock
- if a graph contains a cycle: system may / may not be in a deadlocked state
- if only one instance per resource type: then deadlock
- if several instances per resource type: possibility of deadlock
Deadlock handling
-
Methods for handling deadlocks
- ensure that: system will never enter a deadlock state
- deadlock prevention: ensure at least one of the necessary conditions cannot hold
- deadlock avoidance: requires additional information
- given in advance, concerning
- deadlock detection: allow system to enter a deadlock state
- periodically detect: if there is a deadlock & recover from it
- 👨🎓 ~= garbage collector?
-
- ensure that: system will never enter a deadlock state
-
Deadlock prevention
- mutual exclusive: unavoidable
- some resources: cannot be shared!
- hold & wait: must guarantee: whenever a process request a resource, it doesn't hold any other resources
- require: each process to request and allocated all its resources before execution
- request resources only when process: has none
- disadvantages: low resource utilization, possible starvation
- require: each process to request and allocated all its resources before execution
- no preemption:
- preempt resource occupied by another resource
- preempted resource: added to waiting resource
- process: will be restarted only if all its old resources are regained
- only for resources w/ state being easily saved & restored
- e.g. registers, memory space, and DB transactions
- cannot be generally applied ro resource (e.g. locks, semaphore)
- preempt resource occupied by another resource
- circular wait: impose total ordering of all resource types
- require: each process requests resources in an increasing order of enumeration
- thus: must request before if
- can be proved by contradiction
- let: set of processes involved in circular wait:
- : awaiting for , held by process
- : waiting for held by
- implies:
- : impossible
- thus, there can be no circular wait
- 👨🏫 same problem as hold & wait: very slow
- problem: request resource much earlier than needed / expected
- require: each process requests resources in an increasing order of enumeration
- mutual exclusive: unavoidable
-
Circular wait example
- invalidating circular wait condition: most common
- assign each resource (i.e. mutex locks): unique number
- resources: must be acquired in order
- code
first_mutex = 1 second_mutex = 5
- invalidating circular wait condition: most common
-
Deadlock avoidance
- requires: system w/ additional a priori information available
- e.g. w/ knowledge of complete sqe. of request and release for each process
- system: can decide for each request whether process should wait to avoid a possible future deadlock
- simples & most useful model:
- requiring each process declaration on max no. of resources of each type
- that it might need (worst case)
- deadlock avoidance algorithm: dynamically examining resource-allocation state
- de ensure: circular-wait condition can never exist
- e.g. w/ knowledge of complete sqe. of request and release for each process
- resource allocation state: defined by
- available resources
- allocated resources
- max demand of processes
- requires: system w/ additional a priori information available
-
⭐⭐ Safe state
- when a process: request an available resource
- system: must decide whether allocation will leave system in safe state
- system: in safe state if there exists a safe sequence consisting all processes in systems
- s.t. for each , resource can still request:
- can be satisfied by currently available resources + resources held by all for
- i.e. can be freed by execution of
- 👨🏫 : not waiting for anybody
- can be satisfied by currently available resources + resources held by all for
- 👨🏫 procedure: find s.t. it can be executed w/o any need for waiting
- s.t. for each , resource can still request:
- i.e. if : resource needs not immediately available:
- : can wait until all have finished
- when finished: obtain needed resources, execute, return allocated resources & terminate
- when terminates, : obtain needed resources, and so on
- if no such seq. exist: system state is unsafe
- 👨🏫 not saying that there must be a deadlock
- i.e. no immediate solution found!
- ⭐ basic facts
- if system is in safe state: no deadlocks
- if a system is in unsafe state: possibility of deadlock
- when a process: request an available resource
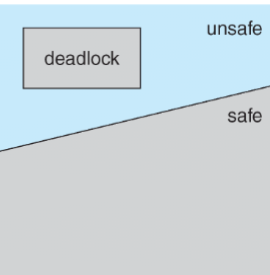
Algorithms
-
Avoidance algorithms
- single instance of a resource type
- use resource allocation graph
- multiple instances of a resource type
- use Banker's algorithm
- single instance of a resource type
-
Resource-allocation graph scheme
- simply check: whether there exists a cycle
- 👨🏫 if so: deadlock!
- simply check: whether there exists a cycle
-
Banker's algorithm
- multiple instances
- each process: must declare priori maximum usage
- if resulting state is unsafe: don't allocate resource!
- when process requests a resource: wait
- check if: allocation result in a safe state / not
- when process
- similar to banking loan system
-
Data structure for Banker's algorithm
- : no. of processes, : no. of resources types
- available: vector of length
- if
available[j] = k, then instances of type available
- if
- max: matrix
- if
Max[i,j] = k, then may request at most instances of
- if
- allocation: matrix
- if
Allocation[i,j] = k, currently allocated instance of
- if
- need: matrix
- if
Need[i,j] = k, then may need more instances of tom complete tasks - ⭐⭐
Need[i,j] = Max[i, k] - Allocation[i, j] - maximum s.t. process can request additionally
- ensure: the accumulated request doesn't exceed maximum
- i.e. check validity / legitimacy
- ensure: the accumulated request doesn't exceed maximum
- if
- 👨🏫 above properties: defines snapshot
-
Safety algorithm
- input: state
- let work & finish: vectors of length
- initialize:
Work = AvailableFinish[i] = falsefori ∈ [0, n-1]
- initialize:
- find s.t. both
Finish[i] = falseNeed_i ≤ Work
Work = Work + Allocation_iFinish[i] = true- go to step 2
- if
Finish[i] == truefor all : system is in a safe state- otherwise, unsafe
-
Resource-request algorithm for process
- input: request
- request: request vector for process
COMP 3511: Lecture 17
Date: 2024-10-31 15:06:38
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Algorithms (cont.)
-
Resource-request algorithm for process
- : request vector for process
- : : wants instances of resource type
- steps
- d
- verify validity / legitimacy
- d
- verify availability
- d
- verify availability
- basic idea:
- check validity
- verify availability
- execute
- deallocate resources upon termination
- d
- 👨🏫
- safe sequence: may not be unique
- d
- : request vector for process
-
Examples
Deadlock Detection
-
Deadlock detection
- deadlock prevention / avoidance: expensive!
- thus system may provide:
- algorithm examining state of system
- to determine: a deadlock can occur
- algorithm to recover from deadlock
-
Single instance of each type
- maintain: wait-for graph
- nodes being processes
- if : waiting for
- periodically invoke algorithm to detect a cycle
- as cycle iff deadlock for this case
- detecting cycle: runs in time
- : no. of vertices
- wait-for graph: not applicable for system with multiple instances of same type
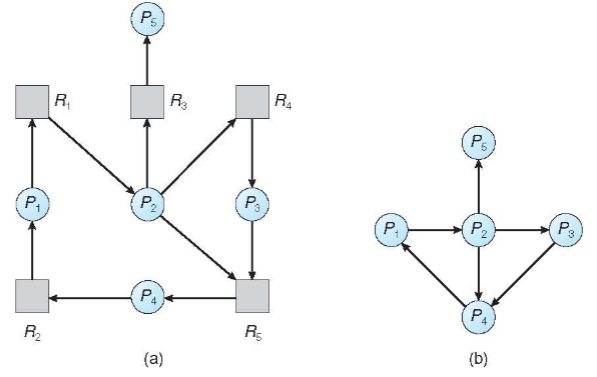
- maintain: wait-for graph
-
Several instances for a resource type
-
Detection algorithm
- steps
- d
- algorithm: requires operations to detect system in deadlocked state
- steps
-
Example
- d
- d
-
Detection-algorithm usage
- when & how often should the algorithm run?
- depending on likeliness of deadlock
- d
- invoking deadlock
- d
- when & how often should the algorithm run?
-
Recovery from deadlock: process termination
- abort all deadlocked process
- abort one process at a time, until deadlock cycle is eliminated
- in what priority?
-
Recovery from deadlock: resource preemption
- successively preempting some resources from processes
- and give the resource to other processes until deadlock cycle is broken
- selecting a victim
- rollback
- starvation
- d
- 👨🏫 some resources cannot be compromised: e.g. semaphore
- others, like memory, can be saved into HDD and loaded later
- successively preempting some resources from processes
-
Remarks
- in PC: restart computer or terminate some process
- thus doesn't run deadlock avoidance
- yet, our focus is on mainframe computers
- were computation is done as a service
- in PC: restart computer or terminate some process
Main Memory
-
Background
- main memory: central to operation of computer systems
- especially for Von Neumann!
- memory: consists of a large array of bytes
- each w/ its own address: byte-addressable
- program: brought into memory
- then placed within a process for run
- i.e. PCB: points to address space of process
- typical instruction execution cycle: include
- memory management unit / MMU: only sees stream of addresses
- not knowing how it's generated
- e.g. instruction counter, indexing, etc.
- only interested in ins. of memory addresses generated by a running program
- not knowing how it's generated
- main memory (+cache) and registers: only storage w/ CPU's direct access
- MMU: sees steam of addresses, read requests, or write requests and data
- memory protection: required to ensure correct operation
- must ensure: OS memory space is protected from user processes
- early DOS system didn't thus crashed often
- minimum protection
- as well as one user process from one another
- protection: shall be provided by hardware for performance / speed
- must ensure: OS memory space is protected from user processes
- main memory: central to operation of computer systems
-
Per-process memory space: separated from each other
- separate per-process
- legal range of address space: defined by base and limit registers
- d
- most basic memory protection!
- d
- hardware address protection
- runs:
≥ base && < base + limit- if false: results in addressing error
- runs:
-
Address binding
- 👨🏫 multiple methods existed historically
- usually: program resides in disk as a binary executable
- most systems
-
Multi-step processing of a user program
- address binding: can execute in 3 different stages
- compile time
- 👨🏫 because MS-DOS only ran one process!
- link / load time
- execution time
- started doing so 30 years ago
- compile time
- address binding: can execute in 3 different stages
-
Address translation and protection
- in uni-programming era: no need for address translation
- early stage of multi-programming
-
Logical vs. physical address space
- address space:
- all addresses a process can "touch"
- each process: w/ their own unique memory address space
- kernel address space
- address space: starts from 0 (logically)
- thus: two views of memory exist
- logical address: generated by the CPU / aka virtual address
- physically address: address seen by the memory
- translation: makes protection implementation much easier
- ensures: process cannot access another process's address space
- compile-
- address space:
-
Memory management unit
- MMU: hardware mechanism: maps virtual address to physical, at runtime
- many different mapping methods: to be covered
- simplicity: consider relocation register
- d
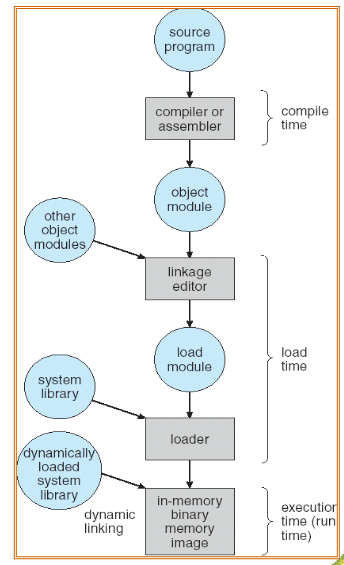
Contagious Memory Allocation
-
Contiguous allocation
- early memory allocation methods
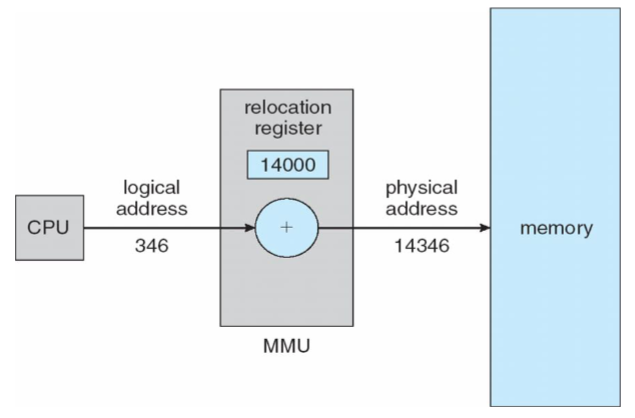
- main memory: divides into two partitions
- one for OS, another for user processes
- many OS: place the OS in high memory
- each process: contained in a single section of memory
- that is contiguous to section containing the next process
- multiple-partition allocations
- degree of multiprogramming: bounded by no. of partitions
- variable partition sizes (depending on a process' needs)
- hole: block of available memory - scattered throughout memory
- when a process arrives: allocated memory from a hole
- s.t. it can reside contiguously
- process exiting: frees its partition
- adjacent free partitions: combined
- OS: maintains information about:
- allocated partitions
- free partitions (hole)
- problem: sufficient holes might not exist, although sum of them are big
- i.e. external (from process's view)
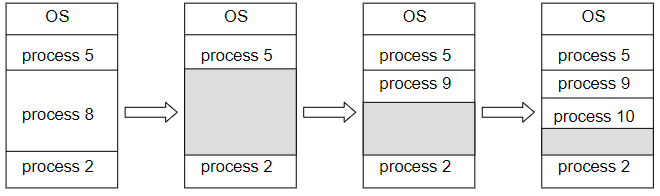
-
Dynamic storage allocation problem
- satisfy: request of (variable) size from list of free holes?
- first fit: allocate the first hole that is big enough
- best fit: allocate the smallest hole that is big enough
- must search entire list
- worst fit: allocate the largest hole that is big enough
- must search entire list
- produces: largest leftover hold
- intended for: reusing remaining hole
- best & worst: name doesn't reflect their value!
- yet, experiments have shown: first & best fit are better than worst fit
- in deceasing time & storage utilization
- generally, first fir is better
-
Fragmentation
- external fragmentation:
- internal fragmentation:
- reducing external fragmentation:
- problem: address space being contiguous
Segmentation
-
Segmentation: user view
- 👨🏫 simple extension of contagious
- MMS: supports user view of memory
- program: a collection of segments (logical unit)
- e.g. main program, procedure, function, method, stack, etc.
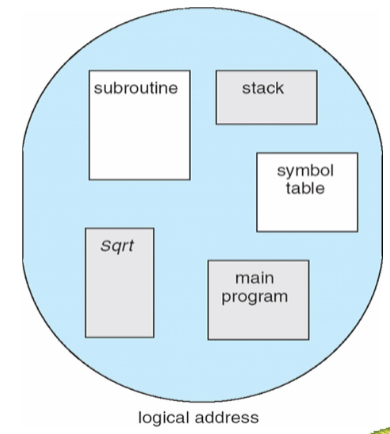
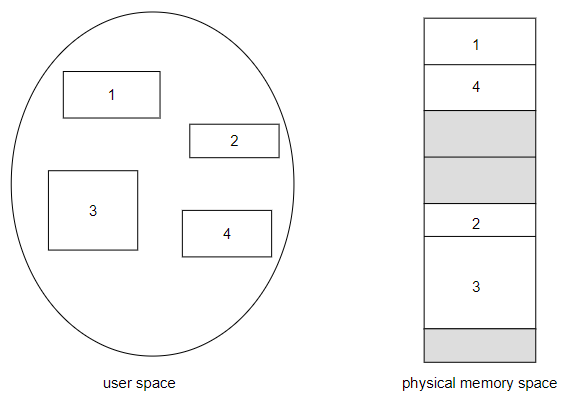
- problem: still exists, yet less severe
-
Segmentation architecture
- logical address: now consists of a two-tuple
- segment table:
COMP 3511: Lecture 18
Date: 2024-11-05 14:24:18
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Segmentation
-
Segmentation architecture
- logical address: consists of
two-tuple- segment-number, offset
- segment table: maps 2D programmer-defined address into 1D physical address
- each entry: contains:
base: containing starting physical address of each segmentlimit: specifying length of segment
- each entry: contains:
- both STBR / STLR: stored in PCB of a process
- segment-table base register (STBR): points to segment table's location in memory
- segment-table length register (STLR): indicating no. of segments used by program
- segment no. : legal if
- protection: each entry in segment table associating w/
validation bit = 0: illegal segment- 👨🏫 part of protection bit
- read / write / execute privileges
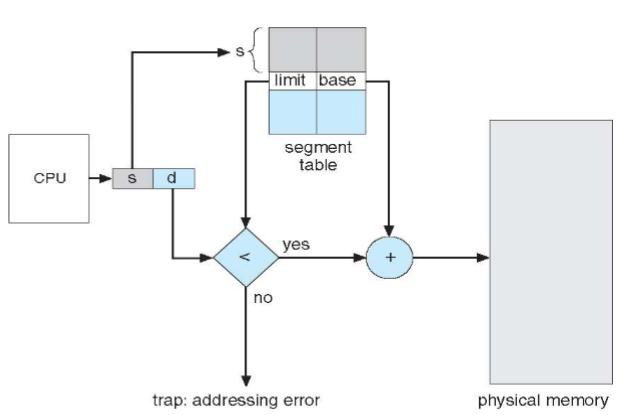
- protection bit: associated w/ each segment
- code sharing: occurring at segment level
- each segment: vary in length
- thus dynamic storage allocation problem still exists
- yet, much less severe as each segment: considerably smaller than entire memory space
- process: might share data
- simply use same base & limit in segmentation table for shared segment!
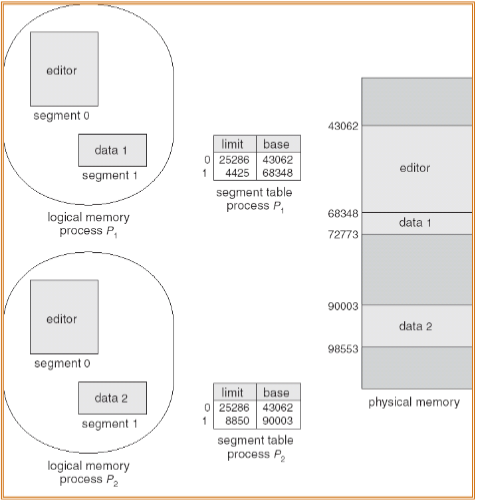
- logical address: consists of
-
Summary segmentation
- protection: easy in segment table
- code segment: read-only
- data & stack: read-write, etc.
- address: can be outside valid range
- as stack & heap: allowed to grow
- system automatically increase the size of stack
- main program w/ segmentation
- dynamic storage allocation problem and external fragmentation persists
- may move processes multiple times to fit everything
- from processor view: good & easy
- protection: easy in segment table
Paging
-
Paging
- divide physical memory into fixed-sized blocks: frames
- usually power of 2: between
4 KB(12 bit offset) to1 GB(30 bit offset)- defined by the hardware
- 👨🏫 frame number: unique in physical address
- usually power of 2: between
- divide logical memory into: blocks of same-size pages (same size as frame)
- OS: keep track of all free (physical) frames available in main memory
- to run program of size pages: find free frames (non-contiguous) in memory
- page table: used for translating logical to physical address
- yet: suffers from internal fragmentation in last page / frame
- divide physical memory into fixed-sized blocks: frames
-
Address translation scheme
- address generated by CPU: 2 parts
- page number (p): index for page table
- containing base address of each page in physical memory
- page offset (d): combined w/ base address to define physical memory
- page number (p): index for page table
page number page offset - page size / frame size: fixed
- same for size of page
- for bits logical address, logical address space: bytes
- if page size / frame size
- no. of pages:
- example
- let page no. -bit, page off set -bit
- then page size: KB
- 32 bit virtual address: shows GB
- 20 bits for page no.: no. of pages
- address generated by CPU: 2 parts
-
Paging hardware
- steps:
- extract page no. and use it for page table index
- extract corresponding frame no. from page table
- replace page no. with frame no.
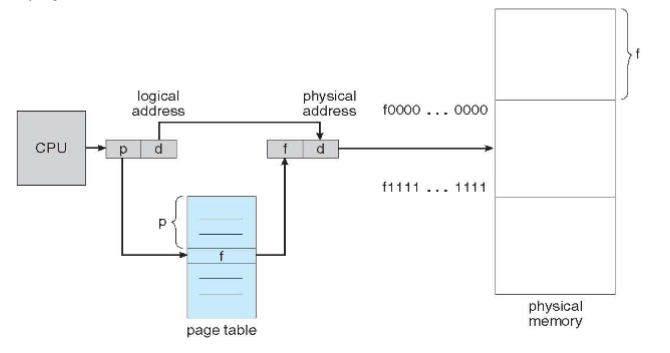
- offset : doesn't change, but replaced
- frame no. & offset: not gives physical address
- steps:
-
Paging example

- frame no.: automatically derive from starting address of each frame
- : means logical address of bytes
- logical address : page 0 & offset 0
- page 0 = frame 5 (from table)
- logical address 0: physical address
5<<n + 0 = 20 - logical address
3=(0,3): physical address5<<n + 3 = 23 - logical address
4=(1,0): physical address6<<n + 0 = 24 - logical address
13=(3,1): physical address2<<n + 1 = 9
- : each page size: bytes
- calculating internal fragmentation
- page size:
2,048bytes (2KB) - process size:
72,766bytes - 35 pages + 1086 bytes
- internal fragmentation:
2,048 - 1,086 = 962bytes - worst case fragmentation:
1 frame - 1 byte - average fragmentation:
1/2 frame
- page size:
- is small frame: desirable?
- page size: grown over time
- SubMicro Solaris: support 8 KB and 4 MB
- process & physical memory view: very different
- for programmer: memory is contiguous
- actually: no
- for programmer: memory is contiguous
-
Implementation of page table
- page table: in main memory
- PCB: keep track of memory allocation for process
- page-table base register (PTBR):
- page-table length register (PTLR):
- under the scheme: every data / instruction access requires two memory access
- one for page table (translation) and another for fetching data
- associative memory / translation look-aside buffers
- page table: in main memory
-
Associative memory
- a parallel search
- address translation
- check all entries in parallel
- TLB: shared & used by all processes
- (w/ PID and page number)
- if : in associative register: get frame no. out: (TLB hit)
- else: bring the entry to TLB / memory
- check all entries in parallel
- locality on TLB
- instruction: usually stays on the same page (sequential access nature)
- stack: exhibits locality (pop in & out)
- data: less locality, still quite a bit
-
Paging hardware w/ TLB
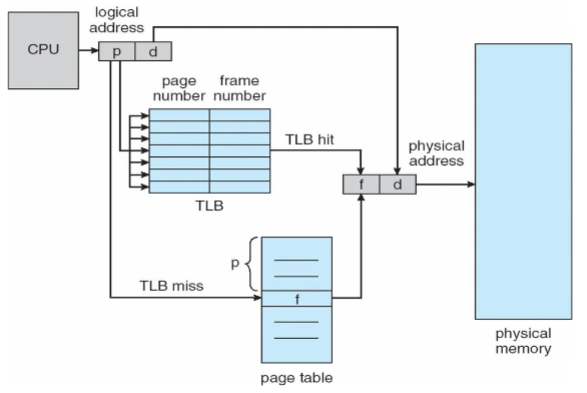
COMP 3511: Lecture 19
Date: 2024-11-07 14:15:25
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Paging
-
Effective access time
- 👨🏫 associative memory: cache!
- associative lookup: time unit
- usually: of memory access time
- hit ratio:
- then effective access time (EAT): memory access time normalized to 1
- e.g.
-
Memory protection
- memory protection: done by protections bits associated w/ each frame
- usually kept in page table
- one bit: define a page to be read-write / read-only
- or: add more bit to indicate execute-only
- valid-invalid bit attached to each entry as well
- valid: indicating a associated page is in process's logical address space
- invalid: indicating a associated page is not in process's logical address space
- OS: sets bit for each page to allow / disallow access to page
- any violations: result in a trap
- e.g. within 14-bit address space, program uses address w/ page size:
- 8 pages
- pages 0-5: valid
- pages 6-7: invalid
- e.g. within 14-bit address space, program uses address w/ page size:
- process: rarely uses all address range
- often: some pages remain almost blank
- creating a page table w/ every page in address range: waste of resource
- most entries: being empty yet taking up memory space
- 👨🏫 use page-table length register (PTLR) to indicate the size of the page
-
Shared pages
- shared code
- private code & data
-
Example: Intel x86 page table entry
- page table entry (PTE): entries of page table
- w/ permission bits: valid, read-only, read-write, write-only
- e.g. Intel x86 architecture PTE
- address: intel x86 architecture PTE
- intermediate page tables: called directories

- explanations
P
- no need to write-back to memory
- 👨🏫 no. of frame: not necessarily same as no. of pages
- more on virtual memory!
- page table entry (PTE): entries of page table
-
Structure of the page table
-
further work
- problem:
- page table:
4 MB = 1000 pages- cannot fit in a single frame!
- kep requesting: must be kept track of
- page table:
- hierarchical paging
- hashed page table
-
-
Hierarchical paging
- break up logical address space: into multiple page tables
- two-level / hierarchical page table: simply paging page table
- 👨🏫 idea: let "part" of page table fit into one page
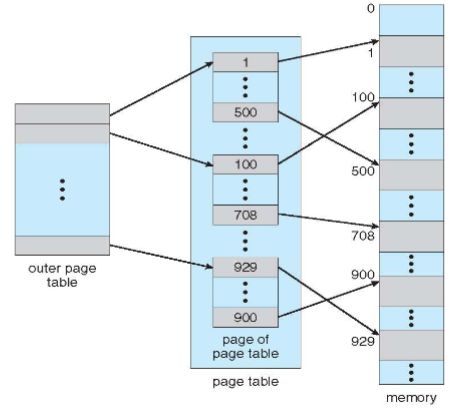
- assumptions
- 32-bit machine w/ 4K page size
- page no.: 20 bits
- page offset: 12 bits
- to page the page table: further divide the page number
- 10-bit page offset : 10 bits if PTE occupies 4 bytes
- ensures: each inner page table: stored within 1 frame / page
- 10-bit page offset : PTE also occupying 4 bytes
- no. of bits in : cannot be more than 10
- 4K = 4 (= 32 bits) * 2^{10} entries
- 10-bit page offset : 10 bits if PTE occupies 4 bytes
- diagram

- :
- penalty: performance from multiple memory access
-
Hashed page table
- common in address space: > 32 bits
- as hierarchical: grows too quickly
- page no.: hashed into a page table
- page table: containing chain of elements hashing into same location
- 👨🎓 linked list!
- 👨🏫 will appear again!
- page table: containing chain of elements hashing into same location
- each element
- common in address space: > 32 bits
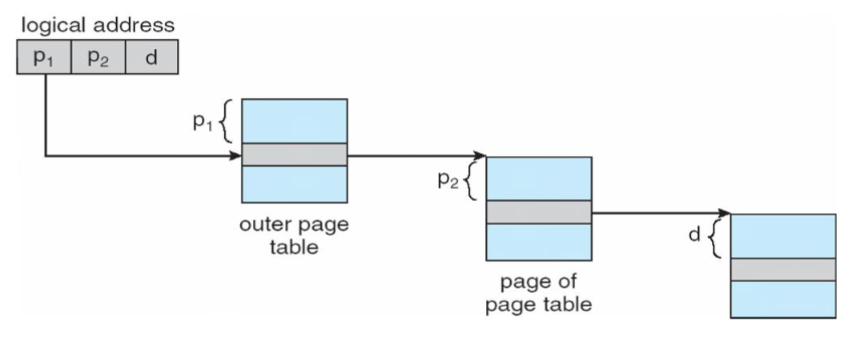
Implementation Examples
-
Example: 32 and 64-bit architecture
- dominant industry chips
- 16-bit Intel 8086 (late 1970s) 8088: used in original IBM PC
- Pentium CPU: 32 bits, aka IA-32 architecture
- supporting: both segmentation & paging
- CPU: generates
- current Intel CPU: 64-bit and called IA-64 architecture
- many variations exist, but only main ideas are covered here
- dominant industry chips
-
Example: Intel IA-32 architecture
- supports: both segmentation & segmentation w/ paging
- each
- logical address: generate by CPU
- supports: both segmentation & segmentation w/ paging
-
Intel IA-32 segmentation

- hardware diagram
- address conversion diagram
- 53-54 bits: used for total of 64 bits
-
Example: ARM architecture
- dominant mobile platform chip
- modern, energy efficient, 32-bit CPU
- 4 KB & 16 KB pages
- two levels of TLBs
- dominant mobile platform chip
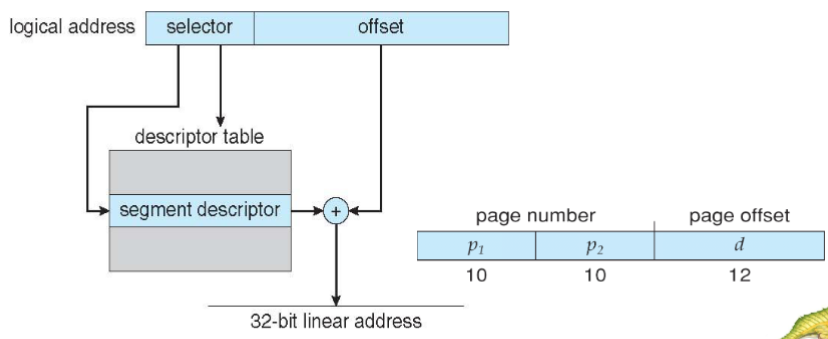
Virtual Memory
-
Background
- 👨🏫 you don't need to load entire program data on memory
- error code / unusual routines: rarely occurring & almost never executed
- 👨🏫 70% of the system programming!
- data structures like arrays / tables: often allocated more memory than need
- certain option / features of program: used rarely
- error code / unusual routines: rarely occurring & almost never executed
- even if entire program is needed: might not be for entire running time
- consider: executing partially-loaded programs
- programs: no longer constrained by limits of physical memory
- programs: can be written w/ extremely large VM address
- each user program: take less physical memory
- more programs can be run simultaneously!
- increasing CPU utilization, degree of multiprogramming, and throughput
- less IO needed to load & swap user program into physical memory
- each user program: runs faster
- programs: no longer constrained by limits of physical memory
- ❓ what if we call
fork()within VM? - virtual memory: separation of user logical memory (aka address space) from physical memory
- more program can be run concurrently
- less IO for load / swap processing
- VM: implemented via:
- demand paging / segmentation: similar in principle
- difference: fixed-size and variable-size frame/page/segment
- demand paging / segmentation: similar in principle
- 👨🏫 you don't need to load entire program data on memory
-
Virtual-address space
COMP 3511: Lecture 20
Date: 2024-11-12 15:01:29
Reviewed:
Topic / Chapter:
summary
❓Questions
- ❓ is page table copied upon clone anyway? can't it be shared?
- 👨🏫 as it's part of PCB, it must be copied.
- in principle, it can be shared
Notes
Virtual Memory
-
Demand paging
- instead of loading the entire process
- bring a "page" into memory only when the page: needed / referenced
- less IO needed
- less memory needed
- faster response
- more users: can be ran
- bring a "page" into memory only when the page: needed / referenced
- similar to: paging system w/ swapping
- page: needed if reference to it is made
- invalid reference (illegal address): abort
- not in memory: bring to memory
- lazy swapper: never swaps a page into memory, unless page is needed
- pager: swapper dealing with pages (unit changed into page, instead of block)
- instead of loading the entire process
-
VM concepts
- pager: brings only those "needed"
- determine the pages to be brought by: modifying MMU functionality
- if pages needed: already memory-resident
- no difference from non demand-paging MMU
- if pages: not in memory
- detect & load page into memory from a secondary storage device
- w/o changing program behavior or code
- detect & load page into memory from a secondary storage device
-
Valid-invalid bit
- w/ each table entry: exists associated valid-invalid bit
v: in-memory (memory resident)i: not-in-memory
- initially: all set to
i- during address translation: if valid=invalid bit is
i:- results in page fault
- during address translation: if valid=invalid bit is
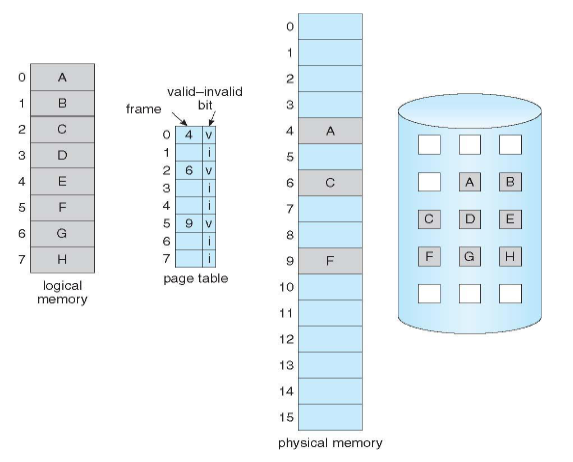
- w/ each table entry: exists associated valid-invalid bit
-
Page fault
- if: any reference of page is made, first reference to the page: traps application into page fault
- it is handled by:
- OS: look at the corresponding PTE
- invalid reference: abort
- else: just not in memory
- get empty frame, if any
- OS: maintains free-frame list
- swap the page (from secondary) into frame via scheduled disk operation
- update the corresponding PTE
- reset page table to indicate: page is now in memory
- set validation bit:
v
- set validation bit:
- restart the instruction caused the page fault
- OS: look at the corresponding PTE
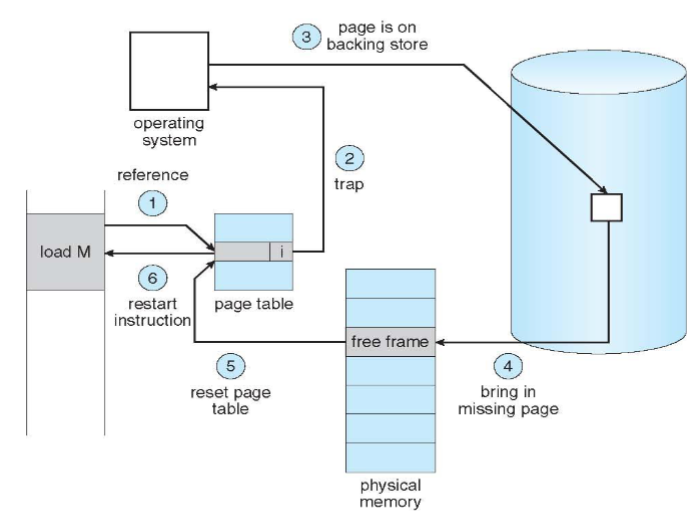
-
Aspects of demand paging
- extreme cse: starts process w/ no pages in memory
- OS: sets instruction pointer to first instruction of process, non-memory resident
- leads to page fault
- same for all other process page, on first access
- aka pure demand paging
- OS: sets instruction pointer to first instruction of process, non-memory resident
- single instruction: could access multiple pages: resulting multiple faults
- e.g. reading two numbers from memory and storing result in memory again
- page faults: decreases as process runs
- due to locality
- to minimize initial / potential high page fault: OS pre-pace some pages into memory
- before process execute
- hardware support needed for demand paging
- page table w/ valid / invalid bit as indication
- secondary memory (swap device w/ swap space) for page in & out
- instruction restart
- extreme cse: starts process w/ no pages in memory
-
Free frame list
- when a page fault occurs: OS must bring desired page into memory
- most OS: maintains a free-frame list: pool
- kernel data structure: only accessible for OS
- OS: typically allocate free-frames w/ zero-fill-on-demand technique
- content of the frame: zeroed-out before re-allocated
- i.e. writing zeros before providing it to a process
- not doing so: leads to potential security issues
- content of the frame: zeroed-out before re-allocated
- when system starts up: all available memory is on free-frame list
-
Performance of demand paging
- stages in demand paging: handle page faults
- trap to the OS
- save user registers & process state (main delay)
- determine: whether interrupt was a page fault
- check if page reference was legal / determine location of page
- issue: a read from disk to free frame
- wait in que for device until read is done
- wait for device seek / latency time
- begin transfer of page to free frame
- allocate CPU cores to other processes while waiting
- receive: interrupt from dis IO (IO: completed!)
- save registers & process state for the other processes
- determine: interrupt was from the dist
- updateL page table & other tables to show page is not in memory
- wait for CPU to be allocated to process again
- restore: user registers, process state, new page table, resume the interrupted instruction
- three major tasks in page-fault service time
- service the interrupt: requires careful coding for efficiency
- read the page: accessing the hard disk (lots of time)
- restart the process: small amount of time
- page switch: probability close to 8 ms for typical hard disk
- page fault rate:
- : no page faults; : every reference is a fault
- effective access time: EAT
- stages in demand paging: handle page faults
-
Computation example
- memory access time: 200 ns
- average page-fault service time: 8 ms
- 👨🏫 roughly 3-4 magnitude difference
- if one access occurs once in a thousand
- , 40 TIMES SLOWER!!
- if we want performance degradation: less than 10 percent
- less than one fault in every 400,000 memory accesses!
- VERY VERY fortunately: memory locality usually satisfies this...
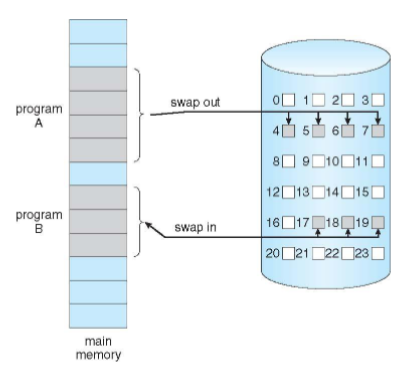
Page Replacement
-
Copy on write
- traditionally:
fork()works by creating a copy of parent's address space - copy-on-write (COW): allows both parent & child to initially share the same page in memory
- shared pages: marked as copy-on-write pages
- if either process writes to shared page: copy of shared page must be created
- original, non-modified page: not left with no sharing
- shared pages: marked as copy-on-write pages
- COW: allows efficient process creation
- only modifies pages getting copied / duplicated
- results in rapid process creation
- w/ minimizing no. of new pages to by allocated to newly created process
- e.g. most child process invoke
exec, so no pages (except PCB) will be copied for them
- e.g. most child process invoke
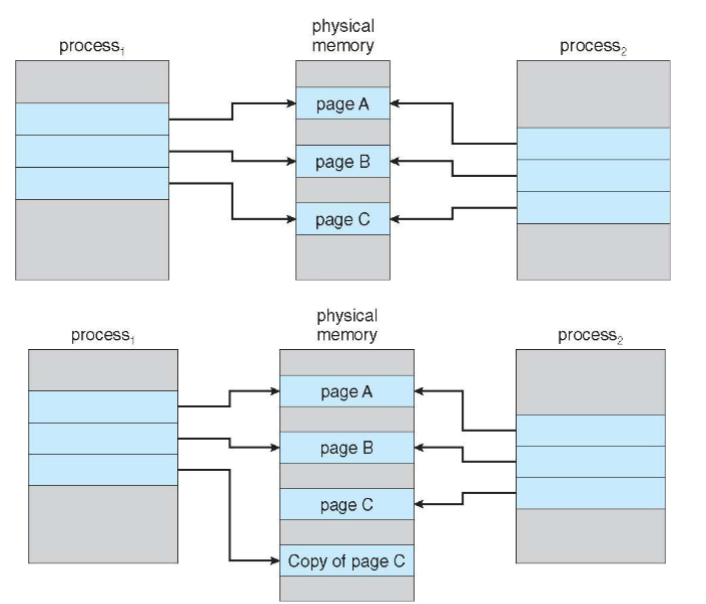
- traditionally:
-
What if: no free frame?
- used up by process pages. kernel, IO buffer, etc.
- how much memory to each memory: frame-allocation algorithm
- page replacement: find some page in memory, and page it out
- algorithms: terminate process? swap out the entire process image? replace the page?
- performance: wish to result in minimum no. of page faults
- must be transparent to process / program execution
- loading same page multiple time: inevitable
-
Page replacement
- prevent: over-allocation of memory by modifying page-fault service routine
- s.t. it include page replacement
- use modify (dirty) bit to reduce: overhead of page transfers
- only modified pages: written back to dist
- page replacement: completes separation between logical memory & physical memory
- large virtual memory: can be supported on a smaller physical memory
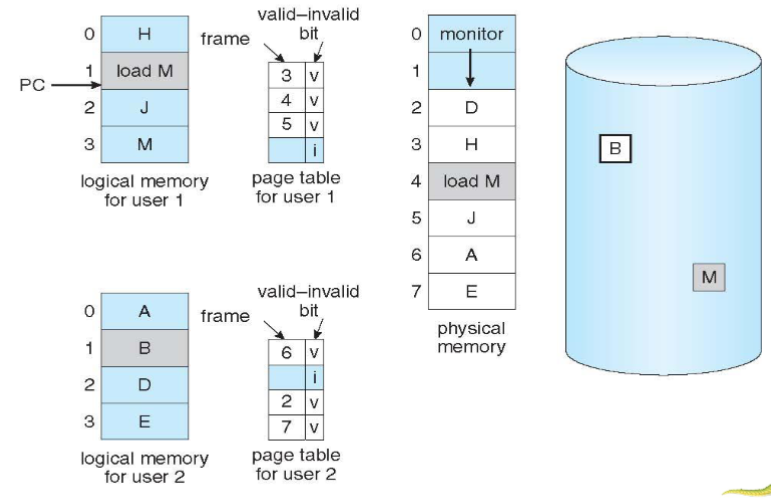
- we must replace some page to load
M
- we must replace some page to load
- prevent: over-allocation of memory by modifying page-fault service routine
-
Basic page replacement
- find the location of desired page on dist
- find: a free frame
- if it exists: use it
- if there is no: use page replace algorithm to select a victim frame
- write victim frame back to dist if it is "dirty"
- bring the desired page into (cleared) free frame; update the page table
- continue the process by restarting the instruction
- potentially: two page transfers for a page fault
- significant increase EAT
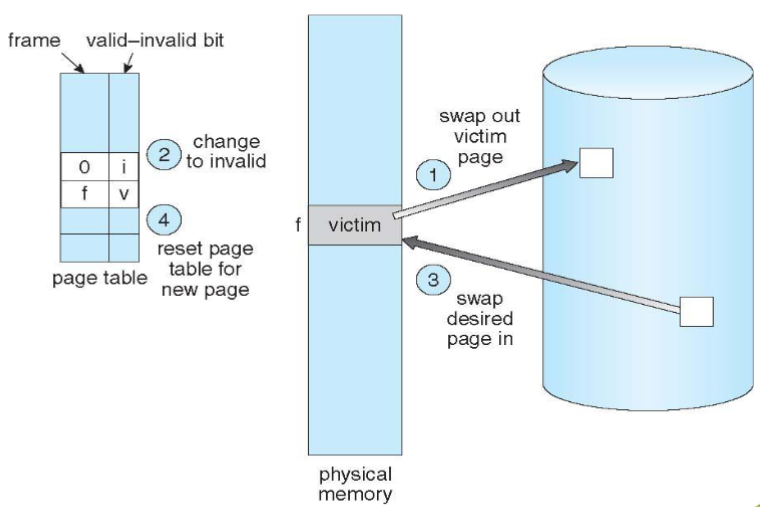
-
Page and frame replacement algorithms
- page-replacement algorithms
- decide: which frame to replace
- objective: minimize the page-fault rate
- frame-allocation algorithm
- determine: how many frames allocate to each process
- decided by how process access the memory (locality)
- determine: how many frames allocate to each process
- page-replacement algorithms
-
Page and frame replacement algorithms
- evaluate algorithms by: running particular string of memory references reference string
- then: compute no. of page faults on that string
- for a given page size: only consider the page number
- as: consecutive reference to the same page never causes a page fault
- thus: having the consecutive page number in string: doesn't make sense
- e.g.
7,0,1,2,0,3,0,4,2,3,0,2,2,1,2,0,1,7,0,1 - no. of page faults vs. no. of frame
- evaluate algorithms by: running particular string of memory references reference string
-
First-In First-Out (FIFO)
- reference string:
7,0,1,2,0,3,0,4,2,3,0,2,2,1,2,0,1,7,0,1 - 3 frames, then 15 page faults
- actual result: would differ by reference string
- adding more frame: can cause more page faults (strange)
- Belady's Anomaly
- e.g.
1,2,3,4,1,2,5,1,2,3,4,5- results in 9 faults in 3 frames, 10 in 4 frames
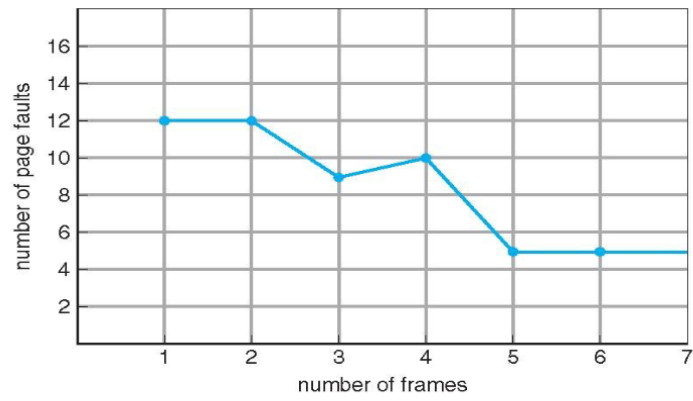
- tracking ages of pages: easy
- use FIFO queue, or some counter, etc.
- reference string:
-
Optimal algorithm
- theoretically optimal, if we know the future!
- replace a page: not used for the longest period in the future
- ideally: choose a page that will not be used at all in the future
- used for: measuring how well your algorithm performs
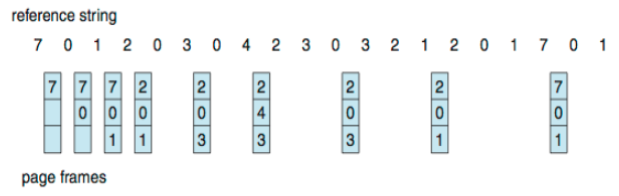
- 9 faults: optimal for 3 frames
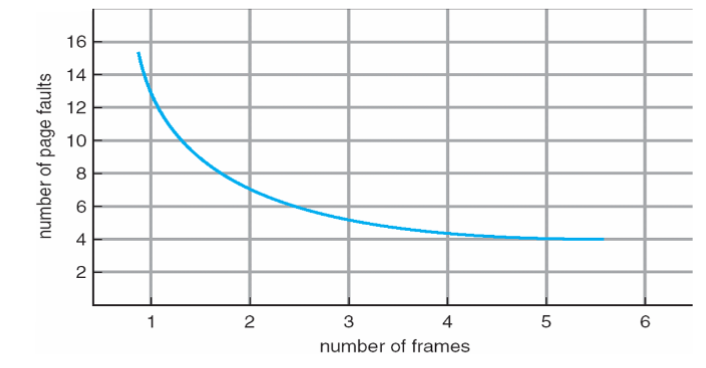
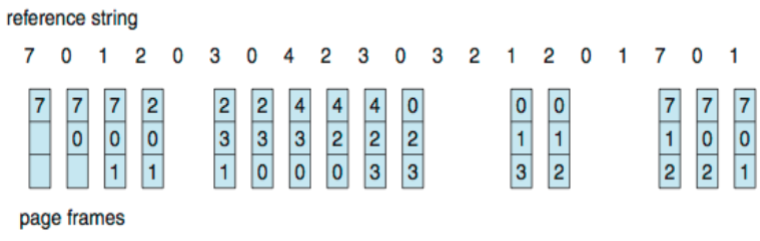
COMP 3511: Lecture 21
Date: 2024-11-14 15:02:44
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Page Replacement
-
Least recently used (LRU) algorithm
- 👨🏫 approximates optimal
- use the past knowledge for approximation for OPT
- 👨🏫 based on locality!
- replace: page that has not been used for the most amount of time
- associate: time of last use w/ each page
- 👨🏫 complex as table: must be updated w/ each memory reference
- associate: time of last use w/ each page
- generally good & frequently used algorithm
- implementation: may require hardware assistance
- determine an order for frames defined by time of last use
-
LRU implementation
- counters implementation
- every page entry: adds time-to-use field recording logical clock / counter
- clock: incremented for every memory reference
- whenever reference to page made: clock registers are copied to time-of-use field
- to choose victim: look for counters w/ smallest value
- every page entry: adds time-to-use field recording logical clock / counter
- stack implementation
- keep: stack of a page number
- whenever a page is referenced: remove from stack
- and put on the top
- most recently used: always at top
- bottom: always at the bottom
- requires: multiple pointers to be changed upon each reference
- each update: more expensive
- yet, no need to search for replacement
- 👨🏫 performance wise, either implementation is "not very good"
- although frequency used
- counters implementation
-
LRU discussions
- LRU / OPT: case of stack algorithms not suffering from Belady's Anomaly
- shows that: set of pages in memory for frame: ALWAYS subset of pages it would have with frames
- for LRU: most recently referenced most recently referenced
- both implementation: requires extra hardware replacement
- updating clock fields / stack: must be done for every memory reference!
- LRU / OPT: case of stack algorithms not suffering from Belady's Anomaly
-
LRU approximation algorithms
- reference bit
- each page: associate a bit (initially 0)
- associated w/ each PTE
- when referenced: set it to 1
- replace any w/ reference bit (if any)
- course-grained approximation:
- order of use: not known
- 👨🏫 what is the least recently used? can't answer always
- course-grained approximation:
- each page: associate a bit (initially 0)
- second-chance algorithm
- FIFO order + hardware-provided reference bit w/ clock replacement
- if page to be replaced has:
ref. bit = 0: replace (as victim)ref. bit = 1: set ref. bit0, leave page in memory- i.e. second chance
- replace next page, w/ the same rule (FIFO + clock)
- 👨🏫 complexity: can be avoided as you can move pointer somewhat - without random accessing
- FIFO itself: not very good, as it doesn't approximate optimal
- advantage: simple implementation
- reference bit
-
Counting algorithms
- keep counter on: no. of references that have been made
- 👨🏫 2 different rationals!
- least frequently used (LFU) algorithm: replaces the page w/ smallest count
- most frequently used (MFU) algorithm: replaces the page w/ most count
- 👨🏫 maybe: it has been already used all!
- neither replacement: commonly used
- expensive implementation & no approximation
- for special systems
-
Allocation of frames
- how to: allocate memory among different processes?
- same freaction, forfifferent?
- should we completely swap some process out of memory?
- each process: needs some minimum no. of frams in order to execute the program
- IBM example
- maximum: total frames required for a process
- two major allocation schemes
- fixed allocation
- priority allocation
- many variations
- how to: allocate memory among different processes?
-
Fixed allocation
- equal allocation
- proportional allocation
- 👨🏫 useless in modern OS!
-
Global vs. local allocation
- global replacement
- process: selects a replacement frame from the set of all frames
- even if the frame: allocated to some other process
- one can take a frame from another process
- e.g. based on priority (priority allocation w/ preemption, basically)
- might result in better system throughput
- yet, execution time many very greatly
- page-fault rate: cannot be self-controlled
- not very consistent!
- process: selects
- process: selects a replacement frame from the set of all frames
- local replacement
- 👨🏫 most common!
- might result in: underutilized memory
- as pages: cannot be utilized to another
- yet: more consistent per-process performance
- global replacement
-
Threshing
- when a process: w/o enough pages
- page-fault rate: will be very high
- leads to low CPU utilization
- OS: "thinks" that degree of multiprogramming must be increased to improve utilization
- 👨🏫 aggravate the problem!
- OS: "thinks" that degree of multiprogramming must be increased to improve utilization
- thrashing: process / set of processes busy swapping pages in & out
- aka high paging activity
- process: thrashing if more time is spent paging than executing
- when a process: w/o enough pages
-
Demand paging & thrashing
- demand paging: warks w/ locality model
- locality model: set of pages that are actively used together
- running program: usually composed of multiple localities over time
- memory access / subsequent memory access: tent to stay ni the same set of pages
- process: migrates from one locality to another
- e.g. operating on different set of data / function call
- locality: might overlap
- locality model: set of pages that are actively used together
- thrashing occurs when:
- size of locality (of all process) total memory size
- allocating not enough frames to accommodate the size of current locality
- effect: can be limited using local replacement
- one: cannot cause other process to thrash!
- locality in memory-reference pattern
- demand paging: warks w/ locality model
-
Working-set model
- working-set window a fixed no. of page references
- e.g. 10,000 instructions
- : working set of process :
- total no. of distinctive pages referenced in most recent
- varies in time
- too small : cannot encompass entire locality
- too large : encompass several localities
- too : encompass entire program
- total no. of distinctive pages referenced in most recent
- total demand frames
- approximation of current locality in the system (of all process)
- if : thrashing (at least one process: short of memory)
- policy: if , then suspend / swap out one of the processes
- working-set strategy: prevents thrashing
- while: keeping the degree of multiprogramming as high as possible
- 👨🏫 CPU utilization: optimized!
- difficulty: keeping track of the working set
- while: keeping the degree of multiprogramming as high as possible
- working-set window a fixed no. of page references
-
Keeping track of the working set
- keeping track of working set: difficult
- as the window: is a sliding window updated w/ each memory reference
- approximate w/ interval timer + reference bit
- e.g.
- timer: interrupts after every time units
- keep in memory: 2 bits for each page
- whenever a timer interrupts: copy & set the values of all ref. bits to 0
- if 1ne of the bits in memory = 1: page in working set
- not accurate, as we can't tell where in interval the reference occurred
- improvement: use 10 bits w/ interrupt every time units
- more accurate, yet more expensive
- accuracy vs. complexity
- keeping track of working set: difficult
-
Page-fault frequency
- more direct approach than WSS
- establish "acceptable" page-fault frequency (PFF) rate & use local replacement policy
- if: actual rate too low -> process loses frame
- if: actual rate too high -> process gains frame
- upon migration to different locality: may be temporary high PFF
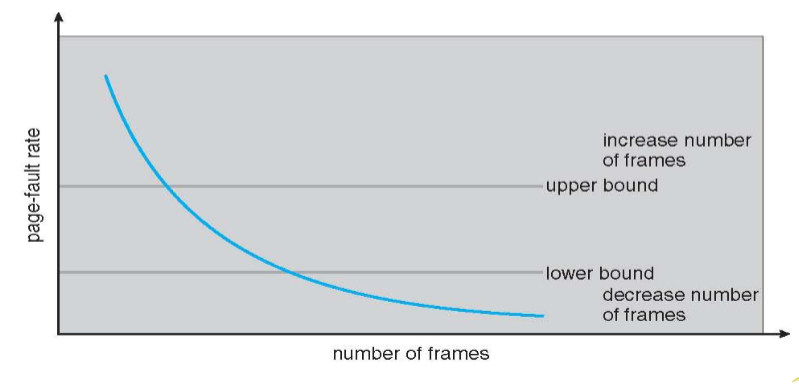
-
Working sets and page-fault frequency
- relationship between working set of a process & page-fault rate
- working set: changes over time
- PFF of process: transitions between peaks & valleys over time
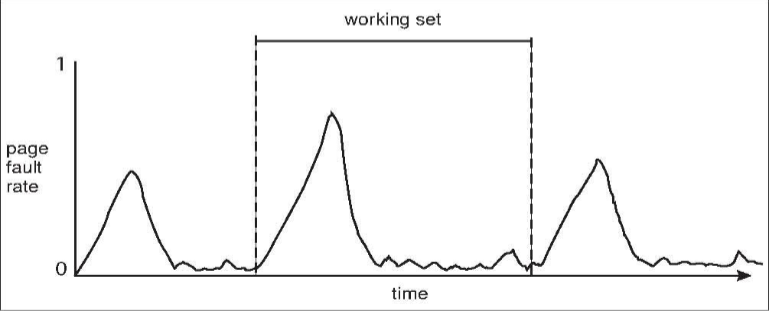
- 👨🏫 only general diagram!
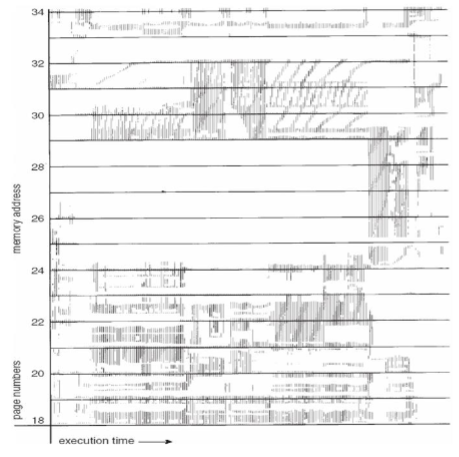
Other considerations
-
Prepaging
- reduce: large no. of page faults occurring at process startup
- prepage some pages the process will need
- before they are referenced
- if: prepaged pages unused => IO & memory wasted
- assume: pages are prepaged, of pages are used
- is cost of save pages faults more than the cost of preparing unnecessary pages
- near 0: prepaging loses
-
Page size
- sometimes, OS designers have a choice
- esp. on custom-built CPU
- page size selection: must consider conflicting set of criteria
fragmentation: calls for smaller page sizepage table size: calls for larger page sizeresolution: isolate the memory actually be used
- always power of 2, usually in range of
- on average: growing over time
- sometimes, OS designers have a choice
-
TLB reach
- TLB reach: amount of memory accessible from the TLB
- TLB reach:
- 👨🏫 ideally!
- ideally: working set working set of each process: stored in the TLB
- otherwise: potentially high degree of page faults / slow access
- increase the page size
- leads to: increase in fragmentation, as not all applications: requires a large page size
- provide multiple page sizes
- allows applications require larger page sizes
- to use larger pages w/o increase in fragmentation
- allows applications require larger page sizes
COMP 3511: Lecture 22
Date: 2024-11-19 14:35:50
Reviewed:
Topic / Chapter:
summary
❓Questions
- ❓ as a programmer, do we need to take locality & page fault into account
- 👨🏫 no, but low level, OS process might need to
- ❓
Notes
Other considerations (cont.)
-
Program structure
Int[128,128] data;- each row: stored in
1 page = 128 objects - program 1 (1 page allocated)
for (j = 0; j < 128; j++) for (i = 0; i < 128; i++) data[i,j] = 0;- picking different row each times
- resulting in: page faults
- d
- picking different row each times
- program 2
for (i = 0; i < 128; i++) for (j = 0; j < 128; j++) data[i,j] = 0;- resulting in: page faults
- once every row change
- resulting in: page faults
Mass Storage Systems
-
Moving head disk mechanism
- each disk platter: w/ flat circular shape
- diameter of 1.8, 2.5, or 3.5 inches
- two surface of a platter: covered with a magnetic materials
- stores information
- read-write head "files": just above each surface of every platter
- heads: attacked to disk arm: moving all heads as a unit
- 👨🏫 back and forth!
- platter surface: logically divided into circular tracks
- then subdivided into hundreds of sectors
- sef of tracks at one arm position: makes a cylinder
- thousands of concentric cylinders in a disk drive!
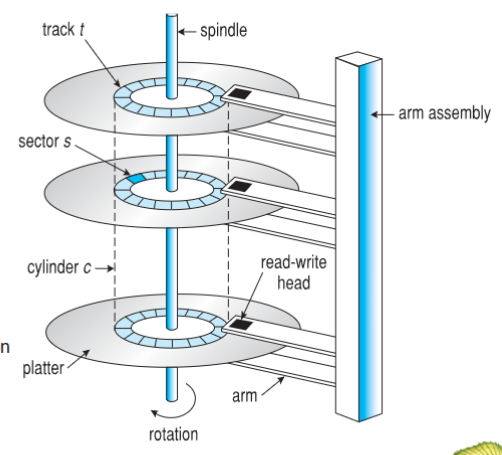

- 👨🎓 lovely!
- each disk platter: w/ flat circular shape
-
Mass storage structure overview
- magnetic disks: provide bulk of secondary storage of modern computers
- drives: rotate at 60-250 times / second
- transfer rate: rate of data flow between drive and computer
- positioning time (random-access time): time to
- move disk arm to desired cylinder (seek time)
- time for desired sector to rotate under the disk head (rotational latency)
- head crush: from disk head making (physical) contact w/ disk surface
- 👨🏫 bad
- disks: can be removable
- drive: attache dto computer via IO bus
- busses: vary
- including EIDE, ATA, SATA, USB, Fibre Channel, SCSI, SAS, Firewire
- host controller in computer: uses bus to talk to disk controller
- disk controller: built into drive / storage array
- busses: vary
- magnetic disks: provide bulk of secondary storage of modern computers
-
Hard disk drive
- platters: range from /85" to 14" (historically)
- commonly: 3.5", 2.5", and 1.8"
- range from: 30GB to 3TB per drive
- performance
transfer rate: (theoretical) 6 Gb / seceffective transfer rate: (real) 1 Gb / secseek time: from 3 ms to 12 ms- average seek time: measured based on 1/3 of tracks
- RPM: typically 5400, 7200, 10000, and 15000 rpm
- latency: based on spindle speed
- 1 / (RPM / 60) = 60 / RPM
average latency: 1/2 latency- e.g. 7200 RPM = 120 rps
- average latency:
1/2*1/120 = 4.17mini-seconds
- average latency:
spindle (rpm) average latency (ms) 4200 7.14 5400 5.56 7200 4.17 10000 3 15000 2 - platters: range from /85" to 14" (historically)
-
HDD performance
- access latency / average seek time: average seek time + average latency
- for fast disk:
3 ms + 2 ms = 5 ms - for slow disk:
9 ms + 5.56 ms = 14.56 ms
- for fast disk:
- average IO time: average access time + (amount to transfer / transfer rate) + controller overhead
- e.g. 4KB block on a 7200 RPM disk, w/ 5 ms average seek time & 1 Gb/s transfer rate w/ 0.1 ms controller overhead:
5 ms + 4.17 ms + 4 KB / (1 Gb / s) + 0.1 ms =- (notice: one is bytes, the other bits)
4 KB / (1 Gb / s) = 2^{-15} s = 0.0305 ms
9.27 ms + 0.0305 ms = 9.3 ms- taking average 9.3 ms to transfer 4 KB, w/ effective bandwidth of 4 KB / 9.3 ms ≈ 3.5 Mb / sec only
- w/ transfer rate at 1 Gb/s given the overhead
- huge gap in HDD between random & sequential workloads
- a disk w/ 300 GB capacity, avg. seek time 4 ms, RPM 15,000 RPM = 250 RPS (avg. latency = 2 ms), transfer rate 125 MB/s, 4KB read at random location
- average IO time = 4 ms + (4 / 125,000) s + 2 ms = 6.03 ms
- effective bandwidth: 4 KB / 6 ms = 0.66 MB/s
- w/ sequential access of a 100 MB file: one seek & rotation needed (ideally)
- can yield: effective bandwidth / transfer rate close to 125 MB/s
- a disk w/ 300 GB capacity, avg. seek time 4 ms, RPM 15,000 RPM = 250 RPS (avg. latency = 2 ms), transfer rate 125 MB/s, 4KB read at random location
- e.g. 4KB block on a 7200 RPM disk, w/ 5 ms average seek time & 1 Gb/s transfer rate w/ 0.1 ms controller overhead:
- access latency / average seek time: average seek time + average latency
-
Solid state disk
- SSD: a nonvolatile memory (NVM) used like a hard drive
- many tech variations, e.g. from DRAM w/ battery to maintain state its state in power failure
- w/ flash-memory technology
- single-level cell (SLC)
- multi-level cell (MLC)
- w/ flash-memory technology
- SSDs: can be more reliable than HDD as no moving / mechanical parts
- much faster: as there is no seek time / rotation latency
- consumes less power: power efficiency
- yet, more expensive per MB, w/ less capacity & shorter life span
- many tech variations, e.g. from DRAM w/ battery to maintain state its state in power failure
- as it's much faster than magnetic disks: standard bus interface mgiit be too slow, being a bottleneck
- some: connect directly to system bus (e.g. PCI)
- some: use them as a new cache tier
- moving data between magnetic disk, SSDs, and memory: for optimizing performance
- SSD: a nonvolatile memory (NVM) used like a hard drive
-
Magnetic tape
- magnetic tape: an early secondary storage medium
- relatively permanent & can hold large quantities of data
- access time: slow
- moving to correct spot might take minutes
- random access: ≈ 1000 times slower than magnetic disk
- not useful for secondary storage in modern computer systems
- mainly used for backup, storage of infrequently used data
- or: medium of transferring information from one system to another
- tape capacities: vary greatly
- depending on particular kind of tape drive
- w/ current capacities exceeding several terabytes
- typically between 200 GB and 1.5 TB
- depending on particular kind of tape drive
- magnetic tape: an early secondary storage medium
Disk Storage & Scheduling
-
Disk structure
- drives: addressed as large 1d arrays of logical blocks
- logical block: smallest unit of transfer
- disk: represented as a no. of disk blocks
- each block: w/ unique block number: disk address
- size of a logical block: usually 512 bytes
- low-level formatting: creates logical blocks on physical media
- disk: represented as a no. of disk blocks
- logical block: smallest unit of transfer
- 1d array of logical blocks: mapped into sectors of the disk (sequentially)
- sector 0: first sector of first track
- on the outermost cylinder
- mapping proceeds in order through track, then rest of tracks in the cylinder
- then rest of cylinders: from outermost to innermost
- logical to physical address (consist of: cylinder number, track number in cylinder, sector no. in track): must be easy, except:
defective sectors: mapping: hides this by substituting spare sectors from elsewhere on disk- no. of sectors / track: may not by constant on some devices
- non-constant no. of sectors / track: via constant angular velocity
- sector 0: first sector of first track
- drives: addressed as large 1d arrays of logical blocks
-
Disk scheduling
- OS: responsible for using hardware efficiently
- for disk drives: meas having fast access time & large disk bandwidth
seek time: time for disk head arm to move the head to corresponding cylinder containing desired sector- measured by:
seek distancein term of no. of cylinders / tracks
- measured by:
rotational latency: additional time for the disk to rotate desired sector to disk headdisk bandwidth: total no. of bytes transferred / total time between first service req. and completion of transfer- improve access time & bandwidth by: managing order of disk IO requests serviced
- many resources of disk IO requests
- from OS, system processes, and user processes
- IO requests: include
- IO modes
- disk address
- memory address
- no. of sectors to transfer
- OS: maintains a queue of requests / disk or device
- in multiprogramming system w/ many processes: disk queue often has several pending requests
- idle disk: can immediately work on IO request
- for busy disk: requests must be queued
- optimization: only when the queue of request exists
- disk drive controllers: w/ small buffers & manage a queue of IO requests (of varying "depth")
- which request to be completed & selected next?
- disk scheduling
- now: illust scheduling algorithms w/ request queue, having
0-199as cylinder numbers- e.g.
98, 183, 37, 122, 14, 124, 65, 67 - current head position:
53
- e.g.
- OS: responsible for using hardware efficiently
-
FCFS / FIFO
- intrinsically: fair, yet doesn't proved the fastest service
- resulting in: total head movement of 640 cylinders
-
SSTF: Shortest seek time first
- selects req. w/ least seek time from current head position
- i.e. pending request closest to current head position
- SSTF: a form of SJF scheduling (greedy)
- may cause: starvation of some requests
- results in: 236 cylinders
- selects req. w/ least seek time from current head position
-
SCAN scheduling
- disk: starting at one end of the disk, moving towards the other end
- on the way: servicing requests as it reaches each cylinder
- at the other end: direction of head movement: reversed, and continue the service
- aka: elevator algorithm
- note: if requests are uniformly distributed across cylinders
- heaviest density of requests: at other end of disk, wait the longest
- must know: direction of head movement
- results in: 236 cylinders
- disk: starting at one end of the disk, moving towards the other end
-
LOOK scheduling
- similar to SCAN, but disk arm only goes as far as the final request in each direction
- NOT the end of the disk
- 👨🏫 guaranteed to be not worst than SCAN
- results in: 208 cylinders
- similar to SCAN, but disk arm only goes as far as the final request in each direction
-
C-SCAN
- Circular-SCAN: provides a more uniform waiting time than SCAN
- head: moves from one end of the disk to the other, servicing requests as it goes
- upon reaching the other end: immediately returns to the beginning of the disk
- not serving any requests on the way back
- treats:cylinders as a circular lists, wrapped around
- from the last cylinder to the first one
- upon reaching the other end: immediately returns to the beginning of the disk
- results in: 382 cylinders
-
C-LOOK
- LOOK version of C-SCAN
- disk arm: goes far as the last request in each direction
- then reversing the direction
- better than C-SCAN, for the very same reason
- results in: 322 (C-LOOK), 308 (LOOK) cylinders
-
Selecting a disk-scheduling algorithm
- common solution: SSTF
- increases performance of FCFS
- SCAN, C-SCAN: performs better for systems w/ heavy load on disk
- as: they are less likely to cause starvation problems
- scheduling performance: depends on the no. o& ype of requests
- w/ 1 request: all scheduling algorithm must behave the same
- requests for disk services: greatly influenced by the file-allocation method (to be discussed)
- contiguously allocated file: generate several requests, close together on the disk
- resulting in limited head movement
- linked or indexed file: may include blocks widely scattered on the disk
- resulting in greater head movement
- location of directories & index blocks: also important
- as: they are accessed frequently
- directory entry and file data on different cylinders
- => cause excessive head movement
- caching directory & index block in memory: helps
- contiguously allocated file: generate several requests, close together on the disk
- disk-scheduling algorithm: written as a separate module of the OS
- allowing to be replaced w/ different algorithm if necessary
- either SSTF / LOOK: a reasonable choice as the default algorithm
- common solution: SSTF
RAID
-
RAID: improving reliability via redundancy
- by: Randy Kal & David Peterson, late 80-90s
- 👨🏫 I know one of them very well
- RAID: Redundant Arrays of Independent Disks
- in the past: composed of small, cheap disks
- viewed as: a cost-effective alternatives to large & expensive disks
- once called: redundant arrays of inexpensive disks
- viewed as: a cost-effective alternatives to large & expensive disks
- now: used for higher reliability via redundancy & higher data-transfer rate (access in parallel)
- in the past: composed of small, cheap disks
- increases: mean time to failure
- by: Randy Kal & David Peterson, late 80-90s
COMP 3511: Lecture 23
Date: 2024-11-21 15:02:33
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
RAID (cont.)
-
RAID (cont.)
- increases mean time to failure
- chance that a disk out of disks fail: much higher than one specific disk failing
- if: mean time to failure of a single disk is 100,000 hours
- mean time to failure in 100 disks: 100,000 / 100 = 1,000 hours = 41.66 days!
- data loss rate: unacceptable if only 1 copy of data is stored
- solution: introducing redundancy
- simply & most expensive approach: mirroring
- duplicate every disk
- every write: carried out on two physical disks
- data: lost only if the second disk fails before first failed disk gets replaced
- mean time to repair
- increases mean time to failure
-
RAID performance improvement
- parallelism (disk system) via data striping: two main goals
- increase: throughout of multiple small access by load balancing
- reduce: response time of large access
- bit-level striping
- array of 8 disks: can be treated as a single disk
- w/ each sectors are 8 times the normal sector size
- bit level striping
- array of 8 disks: can be treated as a single disk
- block-level striping
- blocks of a file: stripes across multiple disks
- with disks: block of a file goes to
- parallelism (disk system) via data striping: two main goals
-
RAID structure
- mirroring: providing high reliability, but expensive
- striping: providing high data-transfer rates, not providing reliability
-
RAID (0+1) and (1+0)
- both striped mirrors (RAID 1+0) or mirrored stripes (RAID 0+1):
- provides high performance (RAID 0)
- and high reliability (RAID 1)
- 👨🏫 can also rely on error correcting code!
- (RAID 0+1)
- (RAID 1+0): drives are mirrored in pairs, and

- both striped mirrors (RAID 1+0) or mirrored stripes (RAID 0+1):
-
Other features
- regardless of what RAID implemented:
- useful features can be added at each level
- snapshot: view of file before the last update took place
- for recovery
- replication
- hot spare: dis
- regardless of what RAID implemented:
File-System Interface
-
File concept
- contiguous logical address space
- types
- data
- numeric
- character
- binary
- program
- data
- content defined by the file creator
- many types: e.g. test, source, and executable file
-
File attributes
name: information kept in human readable formidentifiertype: needed by systems that support different types- 👨🏫 in UNIX/Linux: a positive integer
location: pointer to file location on device- 👨🏫 can be very complex
- depends on: how disk space is allocated to the file!
size: current file sizeprotectiontime, date, and user identification: data for protection, security, and usage monitoring
- information about files: kept in directory structure
- maintained on the disk
- part of which: currently in use can be cached in main memory
- many variations: extended file attributes like file checksum
- maintained on the disk
-
File operations
- file: an abstract data type (ADT)
create:write:read:reposition within file: seek- 👨🏫 not an issue unless you use magnetic tape
delete:truncate:open:close:- such operations: involve changes of various OS kernel data structures
-
Open files
- several data structures: needed to manage open files
open-file tables: tracks open files, system-wide open-file table- and per-process open-file table
- file pointer: pointer to last read / write location
- per process that has the file open
- file-open count: counting the no. of processes that the file has been opened
- allowing: removal of data from open-file table
- when the last processes close it (when file-open count is 0)
- allowing: removal of data from open-file table
- disk locations of a file: cache of data access information
- access rights: per-process access mode information
- several data structures: needed to manage open files
-
File types
file type usual extension function executable usual extension function object usual extension function source code usual extension function batch usual extension function text usual extension function word processor usual extension function library usual extension function print / view usual extension function archive usual extension function multimedia usual extension function -
Access methods
- sequential access: simplest access method
read next write next reset // no read after last write (rewrite) - direct access: file is fixed length logical records
read n write n position to n read next write next rewrite nn: relative block number
- relative block numbers: allows OS to decide where file should be placed
- more in disk block allocation problem
- sequential access: simplest access method
-
Other access methods
- other file access methods: can be build on direct-access
- generally: involve creation of an index for a file
- keep index in memory for fast location of data
- IBM
Structures
-
Directory structure
- collection of nodes containing information about all files
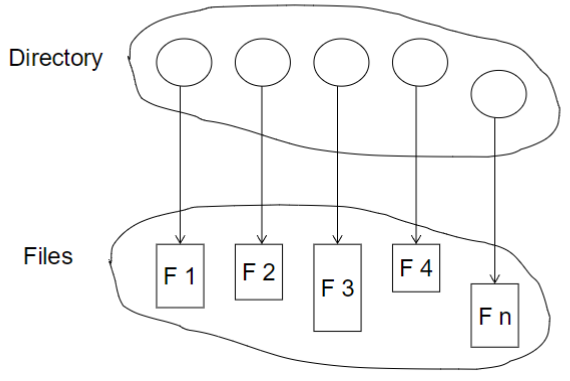
- doth directory structure & files: reside on disk
-
Disk structure
- disk: can be subdivided into partitions
- disks / partitions: can be RAID protected against failure
- partitions: aka minidisks / slices
- volume: entity on a disk containing a file system
- each volume containing a file system: keeps track of the file system into
- in device directory or volume table of contents
- each volume containing a file system: keeps track of the file system into
- other than general purpose file systems, many special purpose file systems exist
- frequently within the same OS / computing system
- 👨🏫 e.g. backup...
-
Typical file-system organization
-
Operations performed on directory
- search for a file
- create a file
- delete a file
- list a directory
- rename a file
- traverse the file system
-
Organize the directory (logically) to obtain..
- efficiency: locating a file quickly
- naming: convenient to users
- two users: might have same name for different files
- same file: can have several different names
- grouping: logical grouping of files by properties
- e.g. all Java programs, games, COMP 3511 ...
-
Single-level directory
- single directory for all users
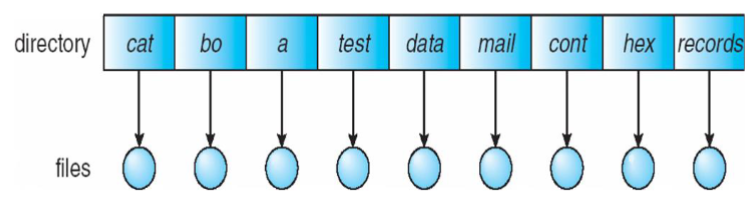
-
Two-level directory
- e.g. separate directory for each user
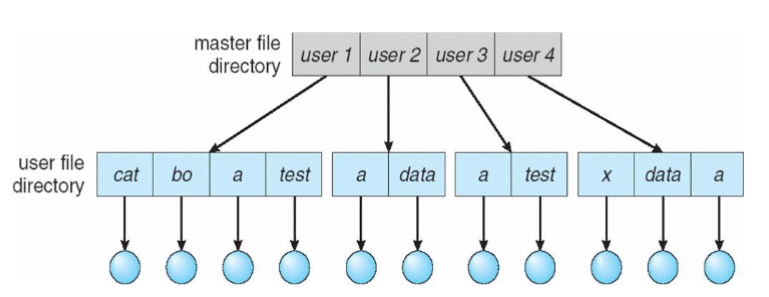
- a path name is required
- to identify files accurately (e.g.
/user1/cat)
- to identify files accurately (e.g.
- same file name may exist under different users
- more efficient searching than single-level directory
- yet no grouping capability
-
Tree-structured directory
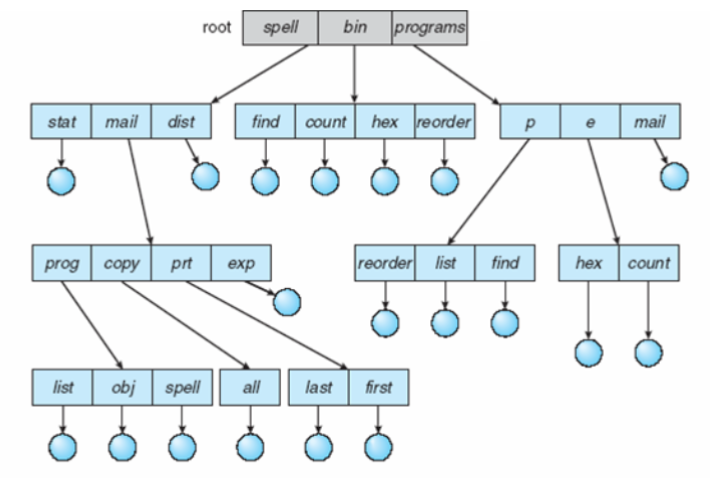
- efficient searching & grouping capability
- current directory (working directory)
cd /spell/mail/prog type list - path name: either absolute or relative
- 👨🏫 absolute: always unique
- creating a new file: done in the current directory
- delete a file in the current directory
rm <file-name>
- creating a new subdirectory: done in the current directory
mkdir <file-name>
- 👨🏫 almost perfect... but it doesn't support shared file!
-
Acyclic-graph directories
- 👨🏫 cycle: must be avoided as we might fall into infinite loop when we traverse!
- now: we have shared subdirectories & files
- more flexile and complex
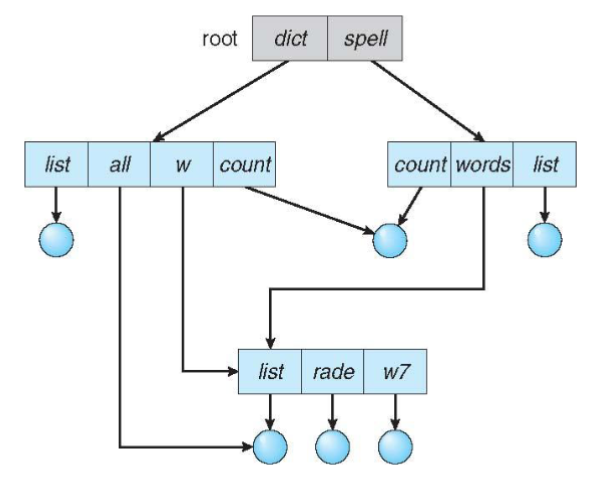
- new directory entry type
- link: another name (pointer) to an existing file
- resolve the link: follow pointer to locate the file
- alias: 2 different path names
- ensure: traversing shared structure more than once
- deletion of one: might lead to dangling pointers
- pointing to empty files, or even wrong files
- also: difficulty ensuring there is no cycle in graph
- either ban directory sharing (inconvenient), or run cycle detection per every new link (time consuming)
- 👨🏫 no free lunch!
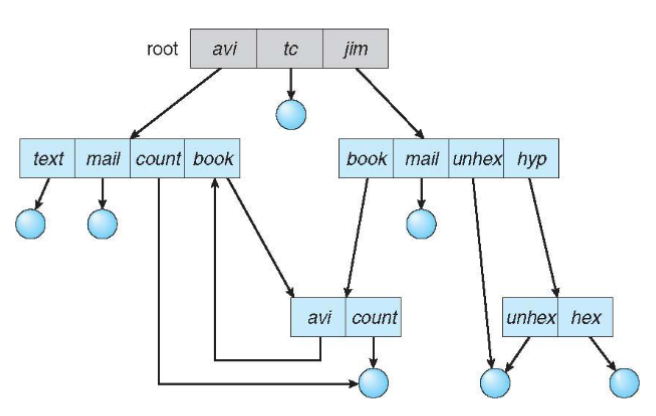
-
File system mounting
-
File sharing
-
Protection
- file owner / creator: should be able to control
- what can be done
- by whom
- types of access
readwriteexecute- as well as...
appenddeletelist
- file owner / creator: should be able to control
-
Access lists and groups
- mode of access: read, write , execute
- a 3-bit integer, or
0-7in decimal - when
bit=1: has permission
- a 3-bit integer, or
- three classes of users: on UNIX / Linux
- owner
- group
- general / public
- thus, 3 3-bit integer to specify permission
- sample
- starts w/
dif directory,-otherwise -rw-rw-r--: file w/664permissiondrwxrwxrwx: directory w/777permission
- starts w/
- mode of access: read, write , execute
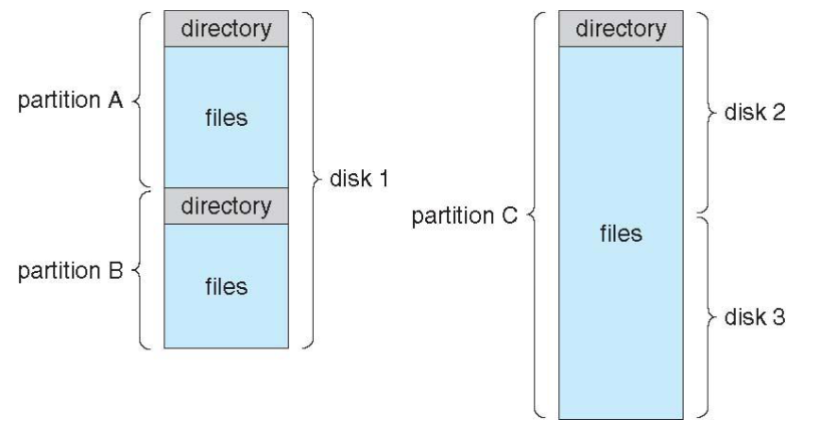
File-System Implementation
-
File system structure
- disk: provides most of second storage
- on which: file systems are maintained
- two characteristics: make disk convenient for this usage
- can be rewritten in place
- can be read from block, and write it back to same place after modification
- disk: can access directly any block of info. it contains
- simple to access any file either sequentially / randomly
- switching from one file to another: requires only moving read-write heads & waiting for disk to rotate
- can be rewritten in place
- to improve IO efficiency: IO transfers between memory & disk: done in units of blocks
- each block: 1 or more sectors
- sector size: varies from 32 bytes to 4KB
- usually 512 bytes
- file structure
- logical storage unit
- collection of related information
- file system: resides on secondary storage (hard drive / disks)
- provides: efficient & convenient access to disk
- by allowing data to be: stored, located, and retried easily
- provides: UI: file and file attributes, operations on files, directory for organizing filed
- provides: data structure and algorithms for:
- mapping logical file system onto physical secondary storage devices
- provides: efficient & convenient access to disk
- file systems: organized into different layers
- disk: provides most of second storage
-
Layered file system
- 👨🏫 multi layer file system: one (not only) way
application programs => logical file system => file-organization module => basic file system => IO control => devices -
File system layers
- IO control & device drivers: manage IO devices at the IO control layer
- basic file system: issues generic commands to the appropriate device driver to read & write physical blocks of dick
- caches: hold frequently used file-system metadata to improve performance
- file organization module: knows files & their logical blocks
- as well as physical blocks
- translates logical block addr. to physical block addr.
- pass this to basic file system for transfer
- managers free disk space
- disk block allocation
- logical file system: manages metadata information
- metadata: includes all of the file-system structure
- except the actual data (i.e. contents of file)
- managing: directory structure to provide: info needed by the file-organization module
- translates: file name into file no. / file handle / location
- by maintaining file control blocks
- file control block (FCB) (aka inode in UNIX)
- contains all info about file, including:
- ownership, permissions, location of the file contents (on the disk)
- also responsible for file protection
- contains all info about file, including:
- metadata: includes all of the file-system structure
COMP 3511: Lecture 24
Date:
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
File-System Implementation (cont.)
-
File system layers (cont.)
- layering: useful for reducing complexity & redundancy
- yet: adding overhead & decreasing performance
- many file systems in use: most OSs support multiple file systems
- layering: useful for reducing complexity & redundancy
-
File system implementation
- several on-disk / in-memory structures are used to implemented a file system
- on-disk structure: "may" contain
- in-memory structure
-
On-disk file-system structure
- boot control block (per volume): contains info needed by system
- to boot OS from that volume
- if: disk not containing an OS: this block can be empty
- typically: first block of a volume
- UFS: calls is boot block
- NTFS: calls is partition block
-
typical file control block
FCB file permissions file dates (create, access, write) file owner, group, ACL file size file data blocks / pointers to data blocks -
s
- boot control block (per volume): contains info needed by system
-
In-memory file-system structure
- information: used for both file-system management & performance improvement
- by: caching
- data: loaded at mount time
- updated during file-system operations
- discarded at dismount
- system-wide open-file table
- per-process open-file table
- buffers: hold file-system blocks
- when being read from disk / written to disk
- opening file: works as follows
open()operation: passes a file name to logical file system- if: file already in use by another process
- per-process open-file table entry created
- points to: corresponding entry of the file
- in system-wide open-file table
- points to: corresponding entry of the file
- else: searches directory structure (might be cached)
- once file found:
- create entry in system-wide & per-process open-file table
- FCB; copy to the system-wide open0file table in memory
- for subsequent access
- system-wide open -ile table: not only stores the FCB
- yet, also tracking no. of processes that opened = using the file
- aka file count
- once file found:
- other field in per-process open-file table: may include a pointer to current location
- per-process open-file table entry created
- 👨🏫 reason for having per-user table: as
- allow multiple users sharing a file
- per-user access right control
open()returns pointer to appropriate entry in the per-process open-file table.
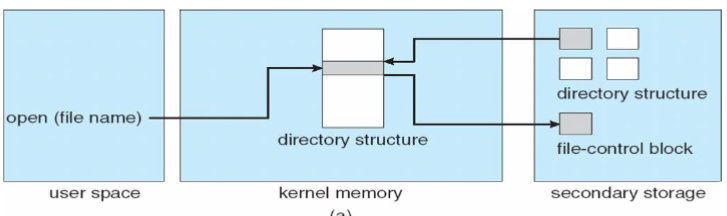
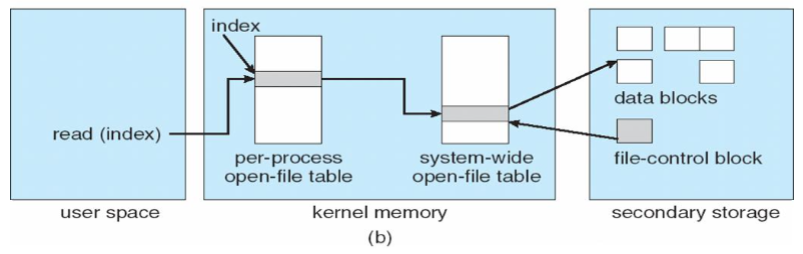
- information: used for both file-system management & performance improvement
-
Directory implementation
- selection of directory allocation & management: significantly affecting efficiency
- as well as efficiency, performance,and reliability of the system
- linear list
- hash table
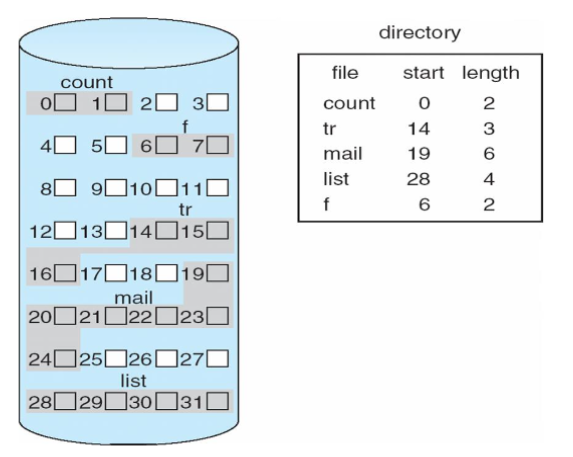
- selection of directory allocation & management: significantly affecting efficiency
Allocation Methods
-
Allocation implementation - contiguous
- disadvantage: memory cannot continue to grow
- like dynamic allocation
- fragmentation, or something, might happen
- disadvantage: memory cannot continue to grow
-
Allocation implementation - linked
- each file : consists of linked-lists of blocks
- benefit: file: can arbitrarily grow
- disadvantage:
- only sequential access is reasonable
- inefficient for direct access of the file
- extra disk space: required for pointers
- let pointer: 4 bytes, out of 512-byte block
- then: 0.78% is use for pointers!
- reliability: another problem
- upon the pointer damage, etc.
- only sequential access is reasonable
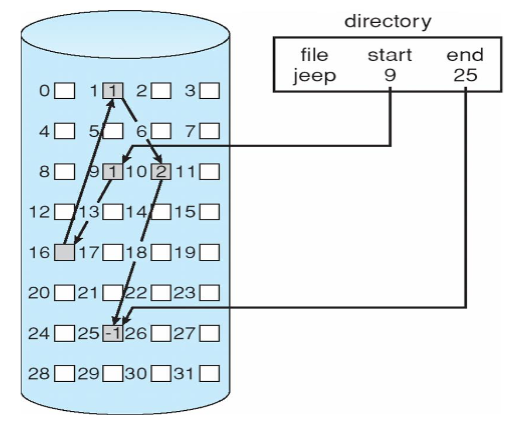
- each file : consists of linked-lists of blocks
-
Allocation methods: FAT
- File Allocation Table (FAT): important variation on linked allocation
- simple & efficient
- idea: create a separate table for indicating "next" block to fetch
- 👨🏫: earlier, yet interesting technology
- small table can be brought to memory / cache, and improving performance
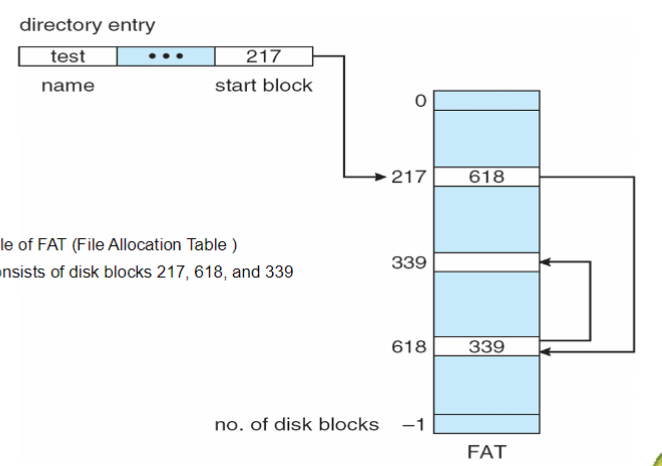
-
Allocation methods: indexed
- indexed allocation: brings all pointers together into one location
- aka index blocks
- obviously, overhead exists
- supports: both random & sequential access
- disadvantage: like page table, hierarchical might be needed
- w/ block size 512 bytes, and pointer of 4 bytes,
- single index block can only contain 128 pointers
- = 64 KiB
- w/ 2 level: blocks
- = 8 GiB
- w/ block size 512 bytes, and pointer of 4 bytes,
- furthermore: as data blocks may be spread oal over a volume
- physical overhead
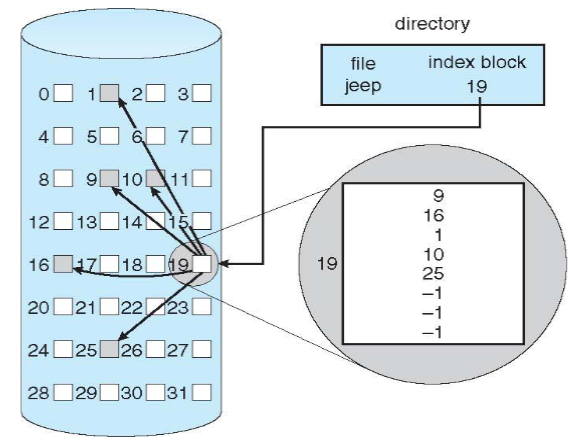
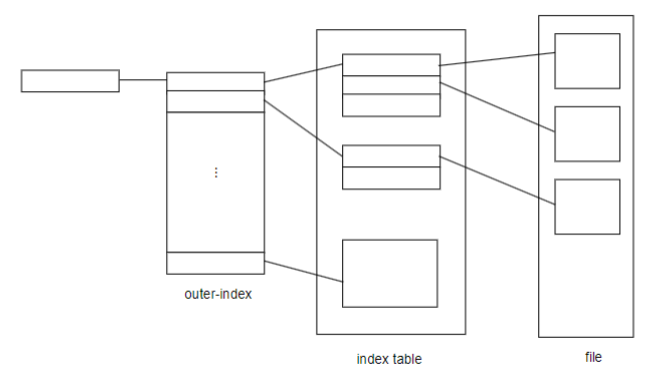
- indexed allocation: brings all pointers together into one location
-
Combined scheme: UNIX UFS
- 4K bytes / block
- 32-bit addresses
- 4KB / 4 = 1024 blocks
- => 4 MB w/ single index
- two-level: blocks
- => 4 GiB w/ single index
- triple level: 4 TiB
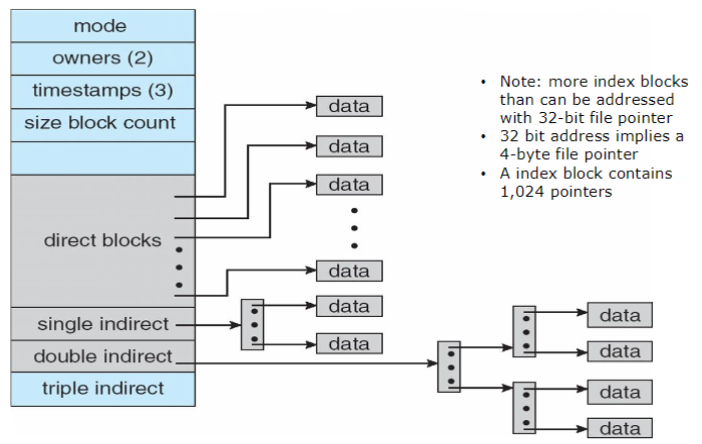
Free Space
-
Free-space management
- file system: maintains free-space list to track free disk space
- used: term "block" for simplicity
- bit vector / map: blocks
- main advantage: simplicity & efficiency
- in finding first free blocks / consecutive free blocks
- bit vector: inefficient unless entire vector can be kept in memory
- yet: it requires extra space
- block size: 4 KB
- disk size: bytes
- bits = 32 MB
- file system: maintains free-space list to track free disk space
-
Linked Free-space list on disk
-
Free-space management: extra techniques
- grouping: modify linked-list
- to store addresses of: free blocks in first free block
- first
- counting: several contig. blocks: may be allocated & freed simultaneously
- particularly: when contig-allocation algorithm / extents is used
- grouping: modify linked-list
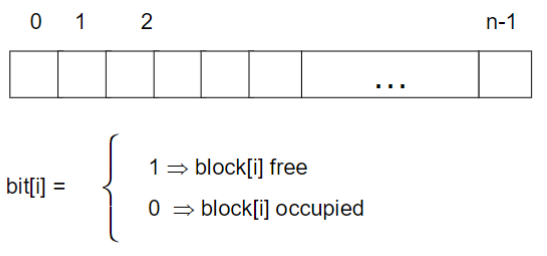
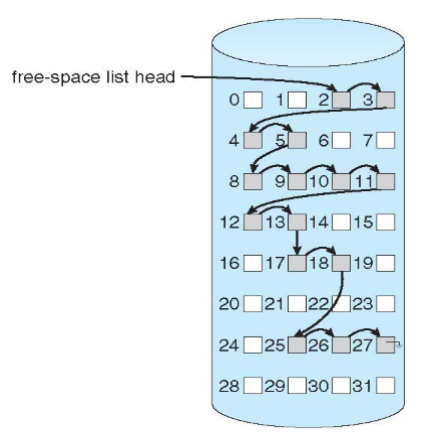
Protection
-
Goals of protection
- in protection model: computer system: made of a collection of objects (HW / SW)
- examples
- each object: w/ unique name & can be accessed w/ well-defined set of operations
- protection problem: ensure each object: accessed correctly & only by those processes allowed to do so
- mechanism: shall be distinct from policies
- mechanism: how it will be dome
- policies: what will be done
- separation: important for flexibility
- separation: ensures not every change in poly would require a change in mechanism
- in protection model: computer system: made of a collection of objects (HW / SW)
-
Principles of protection
- guiding principle: principle of least privilege
- programs / users / systems: shall be given "just enough" privileges
- to perform their task
- mitigating the attack
- file permissions: principle dictates that:
- user: have read access but not write / execute access to a file
- the principle: require the OS to provide mechanism to only allow read access, but not write / execute access
- properly setting permissions (i.e. access rights to an object)
- can limit damage if entity: has a bug / gets abused
- guiding principle: principle of least privilege
COMP 3511: Lecture 25
Date: 2024-11-28 14:53:21
Reviewed:
Topic / Chapter:
summary
❓Questions
Notes
Protection
-
Protection rings
- privilege separation: like user mode & kernel mode
- HW support: required to support notion of separate execution
- let: be any two domain rings
- if
- 👨🏫 hierarchical!
- the innermost ring: ring 0: provides the full set of privileges
- components: ordered by amount of privilege
- & protected from each other
- e.g. kernel & user: different ring
- privilege separation: requires HW support
- "gates": used to transfer between rings
- e.g. syscall instruction, traps, and interrupts
- hypervisor (Intel): introduced
- extended VM managers
- creating & running VM
- more capabilities than kernels of the guest OS
- ARM processors: added TrustZone (TZ) to protect: crypto functions w/ access
-
ARM CPU architecture
-
Domain of protection
- problem: rings being a subset of another
- domain: a generalization of rings without a hierarchy
- 👨🏫 they can be disjoint of one another, too!
- computer system: can be treated as processes / objects
- hardware objects (CPU, memory, disk)
- software objects (files, programs,semaphores)
- process: should only have access to objects it currently requires to complete tasks
- need-to-know principle (policy)
- implementation: via process operating in a protection domain
- protection domain: specifying set of resources a process may access
- each domain: specifying set of objects / types of operations may be invoked on each object
- access right: ability to execute an operation on an object
- domain: collection of access rights, each being an ordered pair
<object-name, rights-set>
- domains: may share access rights
- process-domain associations: can be static
- if set of resources available to the process:
- fixed throughout the process's lifetime
- if set of resources available to the process:
- also: it can be dynamic
- 👨🏫 can support more precise principle of least privilege
- then: some mechanism must allow domain switching
- enables: process to switch from a domain to another
- during different stage of execution
- enables: process to switch from a domain to another
- domain: can be realized in a variety of ways
- each user: may be a domain
- set of objects accessible: depending on user
- domain switch: when the user changes
- each process: may be a domain
- set of objects accessible: depending on process
- domain switch: when a process sending a message to another
- and waiting for a response
- each procedure: may be a domain
- set of objects accessible: depending on local variables defined in procedure
- domain switch: when procedure call is made
- each user: may be a domain
-
Domain structure
- access right
- two domains: independent
- can be disjoint, etc.
Access Matrix
-
Access matrix
- access matrix: view protection: as a matrix
- rows: domains
- columns: objects
access[i,j]: set of access rights of domainion objectj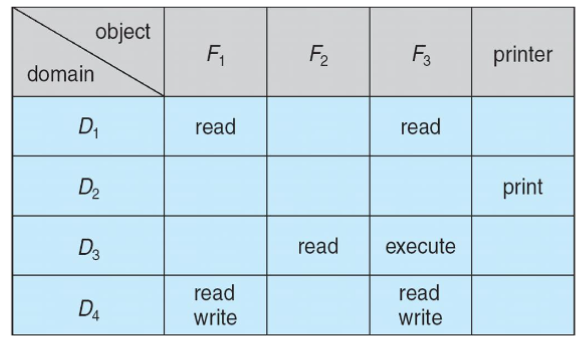
-
Use of access matrix
- access matrix scheme: providing mechanism for specifying a variety of policies
- mechanism: consists of implementing access matrix / ensuring that semantic properties hold
- to ensure a process executing in domain:
- can access only objects specified in row
- to ensure a process executing in domain:
- policy decisions: specify which rights should be included in -th entry
- and determine: domain for each process to execute
- idea: can be expanded to dynamic protection
- operations: to add / delete access rights
- special access rights
- owner of : can add / remove any right in any entry in column
- copy op from (denote:
*)- only within the column (i.e. for the object)
- control: : modify access rights
- modify domain objects (a row)
- transfer: switch from domain
- copy & owner: applicable to an object
- change: the entries in a column
- control: applicable to domain object
- changing entries in a row
- new objects / domains: can be created dynamically
- and included in the access-matrix model
- d
-
Access matrix w/ copy rights
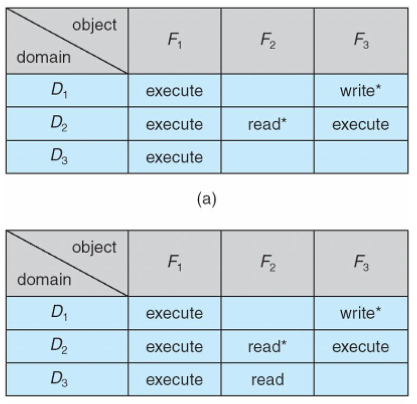
- while executing
readon within domain- it can copy
-
Access matrix w/ owner rights

- as a owner: anything within the column can be changes
-
Access matrix (modified)
- some domain: has control over another domain
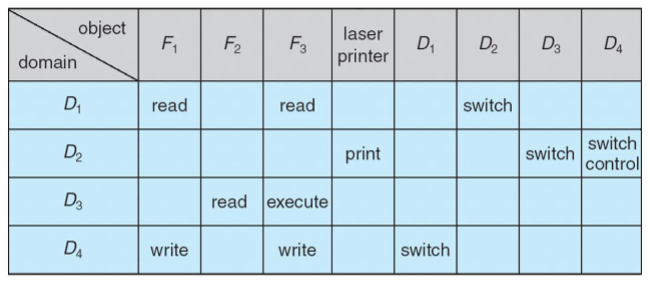
-
Access matrix implementation
- generally: access matrix is sparse
- thus: most of entries will be empty
- option 1: global table
- store: ordered triples
<domain, object, rights-set>in table - requestie op
- each column: Access-control list for one object
- define: who can perform what operation
domain 1: read, write domain 2: read domain 3: read ... - each row: capability list (like a key)
- for each domain: what operations allowed on what objects
object 1: read object 2: read, write, execute object 3: read, write, delete, copy ...- 👨🏫: can be a very long list, as there may be many objects
- store: ordered triples
- option 2: access lists for objects
- each column: implemented as an access list for one object
- resulting per-object list: consists of ordered pairs
<domain, rights-set>- defining: all domains w/ non-empty set of access rights for the object
- empty entries: can be discarded
- also: a default set of access rights can be dreaded
- allow access to any domain, if
M ∈ default set
- allow access to any domain, if
- option 3: capability lists for domains
- instead of object-based: list being domain-based
- capability list for domain: list of object
- together w/ operations allowed on them
- an object: represented by its name / address (capability)
- to execute operation on object ,
- option 4: lock-key
- compromise between: access lists & capability lists
- each object: w/ list of unique bit patterns: locks
- each domain: w/ list of unique bit patterns: keys
- 👨🏫 same for each operations
- match: some binary operation
- without description in text
- process in domain: can only access obj if:
- domain w/ key that matching: one of locks of the object
- 👨🏫 without much description even in the textbook!
- not implemented commonly
- generally: access matrix is sparse
-
Comparison of implementations
- choosing a right technique: involving trade-offs
global table: simple, yet large- lack of grouping of objects / domains
access lists: correspond directly to the needs of users- access list on an object: specified when a user creates the object
- determining set of access rights for each domain: difficult
- every access to the object: must be checked
- requiring: search of the access list
- every access to the object: must be checked
capability list: useful for localizing information for a given process- yet: revocation capabilities can be inefficient
lock-key: can be effective & flexible, depending on the length of the keys- keys: can be passed freely from domain to domain
- easy revocation!
- keys: can be passed freely from domain to domain
- most systems: use combination of access lists / capabilities
- 👨🏫capability list: can be done with hash map
- however: can cause trouble trouble to access-control list
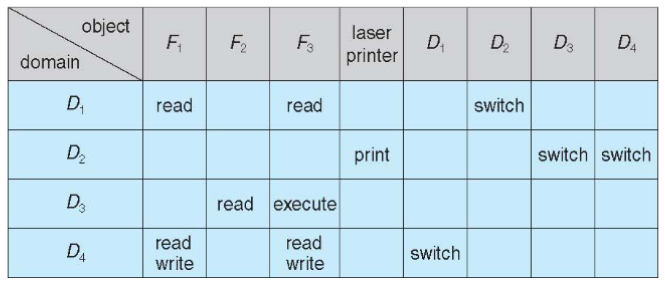
Final exam coverage
-
Final exam
- only post-midterm content is covered
- which is... still quite a lot!
- Ch. 6, 7, 8, 9, 10, 11, 12, 13, 14, 17
- Q&A session: may be arranged